Student Name:___________________Table 2 Rubric
Checklist for “Pass”:
Table dimensions are comparable to the one in Ben’s lecture notes, showing between 4 and 6
different specifications (1 estimate per column) and enabling the reader to compare the 𝛽𝛽̂ s of interest
by reading across one row.
Standard errors are shown on separate rows and in parentheses for each reported coefficient.
Estimates or variables are scaled to prevent padding zeros and scientific notation. Y and X variables
are in functional form noted in topic approval, e.g., logarithms, z scores.
Number of digits reported on estimates is either 3 or 4. If you think your variables present an
exception to this rule, please discuss it with Ben before making your Table.
The lower portion of the table has a row that enables the reader to differentiate the estimates
according to what else is included in the model, like the example below.
o incomplete or poorly formatted, you earn a “low pass” of ½ or “fail” of 0 points.
Table has a Title.
Labels, including rows and cell contents, like those on the template below are tailored to the
individual student’s topic.
Row labels are informative and enable the reader to interpret the 𝛽𝛽̂ estimates (“what is a 1 unit
change?”).
o Row labels that don’t clearly communicate the units and variable definition(s) earn a low pass.
Table has a caption that explains the cells, e.g., what controls are included in “All”?
The overarching objective is to make the Table self-contained. I should be able to look at your Table
without looking up your topic and know what is being regressed on what and how to interpret the
estimates. Anything that isn’t obvious about the sample or the units from looking at the body of the
Table should go in a caption.
Table 2: Label this one “Table 2: Regression Estimates” in your Write-Up
Coefficient
estimate
Controls
Sample Size
Adjusted 𝑅𝑅 2
a
b
̂
̂
𝛽𝛽1|𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠 𝑂𝑂𝑂𝑂𝑂𝑂 𝛽𝛽1|𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠. 𝑏𝑏
(𝑠𝑠. 𝑒𝑒. )
(𝑠𝑠. 𝑒𝑒. )
None
Age
c
̂
𝛽𝛽1|𝑐𝑐
(𝑠𝑠. 𝑒𝑒. )
Age
and
state
d
̂
𝛽𝛽1|𝑑𝑑
(𝑠𝑠. 𝑒𝑒. )
All
Econ 360 Table 2
Brief: I’m writing about the effects of the use of vehicular transport (measured in time spent commuting
to work) and the extent of its effect on a population’s physical fitness and, more specifically, their levels
of obesity (BMI>30).
a
c
d
Coefficient .0070269
-.0030338 -.0022855
estimate
(.0385116) (.0406203) (.0385945)
e
-.0028577
(.0384676)
f
.0132067
(.0410755)
Controls
None
Percent
Access to
Exercise
Percent
Excessive
Drinking,
Percent Access
to Exercise
Percent
High
School
Graduates,
Percent
Excessive
Drinking,
Percent
Access to
Exercise
Adjusted
R2
-0.0107
-0.0149
0.0838
0.0900
Household
Income,
Percent
High
School
Graduates,
Percent
Excessive
Drinking,
Percent
Access to
Exercise
(All)
0.0923
Y=PercentObese=f(log(CommuteTime), PercentAccesstoExcercise, PercentExcessiveDrinking,
PercentHighschoolGraduates, log(HouseholdIncome))
(PercentObese)=β0 + β1log(CommuteTime) + β2(PercentAccesstoExercise) +
β3(PercentExcessiveDrinking) + β4(PercentHighschoolGraduates) + β5log(HouseholdIncome)
Where, in the given county,
Y=PercentObese= Percentage of adults that report a BMI of 30 or more
X1=log(CommuteTime)= Log of the mean travel time to work (minutes)
Control Variables:
X2=PercentAccesstoExercise= Percentage of population with adequate access to locations for physical
activity*
X3=PercentExcessiveDrinking= Percentage of adults reporting binge or heavy drinking**
X4=PercentHighschoolGraduates= Percentage of ninth-grade cohort that graduates in four years
X5=log(HouseholdIncome)= Log of the Median Household Income (US Dollars)
Table 2: Union Rates Effects on Income Inequality
a
Coefficient
estimate
-0.0031
Standard error
0.000742
b
Year
1990
2000
Year
1990
2000
c
-0.0064
0.0632
Year
1990
2000
0.00029
0.07834
0.0111
0.0119
Year
1990
2000
0.01192
0.01546
Observations
152
152
152
Controls
Simple
Year Indicators
Year and
Unemployment
Adjusted R2
0.0935
0.2920
0.2983
GDP and Happiness
a
b
c
d
Coefficient
estimate (B1)
0.19
(.049)
0.2
(.049)
0.19
(.045)
0.19
(.040)
Controls
None
health
health &
cash
all
Adjusted R^2
0.245 0.2545
0.3799
0.505
Included in All are the controls of health (the feeling
of how health the person is feeling) which is coded
as 1 (healthy) 0 (not healthy) cash (have they gone
without a cash income in the past 12 months) which
is coded as 1 (yes) and 0 (no) and lastly technology
(how developed they see their country) which is 1
(yes developed) and 0(no). As you can see the
adjust R^2 increases as the new controls are added
into the regression. Also education is included in the
Simple OLS as B1.
“Table 2: Regression Estimates”
̂
̂
̂
ln(𝑗𝑗𝑗𝑗𝑗𝑗) = 𝛽𝛽0 + 𝛽𝛽1 ln(𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡ℎ) + 𝛽𝛽2 ln(ℎ𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜) + 𝛽𝛽̂3 ln(𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜) + 𝛽𝛽̂4 (𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎) + 𝛽𝛽̂5 (𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢) + 𝜇𝜇
A
B
C
D
“ln(teach)” (𝛽𝛽̂1 )
.1574
-.4911
-.4877
-.4270
(.4133)
(.4353)
(.4286)
(.4437)
% Change on Juvenile
Crime
–
–
–
–
Controls
None
officers
officers, house
All
Observations
58
58
58
58
Adjusted 𝑅𝑅 2
0.00
.1248
.1515
.1273
Table 2 summarizes the regression of juvenile crime rate on the ratio of average K-12 teacher salaries
and per capita income. Column A describes the simple linear regression with no controls. Column B
describes the regression that controls for “officers”. Column C controls for both “officers” and “house”.
Column D controls for all variables stated in the model. The standard errors are provided immediately
below the coefficient estimates. The implied % change on juvenile crime rate is vacant because the
variable of interest was found to be insignificant at 𝛼𝛼 = .1 for all combinations of control variables. A key
for each variable is provided below:
𝑗𝑗𝑗𝑗𝑗𝑗 = 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗 𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 𝑝𝑝𝑝𝑝𝑝𝑝 100,000
𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡ℎ =
𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎 𝐾𝐾 − 12 𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡ℎ𝑒𝑒𝑒𝑒 𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠𝑠
𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 𝑝𝑝𝑝𝑝𝑝𝑝 𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐𝑐 𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖
ℎ𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜 = 𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚 ℎ𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜ℎ𝑜𝑜𝑜𝑜𝑜𝑜 𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖
𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜 =
# 𝑜𝑜𝑜𝑜 𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗𝑗
# 𝑜𝑜𝑜𝑜 𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜𝑜
𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎 = # 𝑜𝑜𝑜𝑜 𝑐𝑐ℎ𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝑝𝑝𝑝𝑝𝑝𝑝 1000 𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟 𝑎𝑎𝑎𝑎 𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎
𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢 = 𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢𝑢 𝑟𝑟𝑟𝑟𝑟𝑟𝑟𝑟
QB
WR
TE
RB
OL
LB
DL
DB
Position Group Effect On Point Differential
a
b
c
34.782
20.326
23.069
(19.054)
(18.960)
(19.639)
35.610
70.645
(33.836)
(36.961)
11.652
43.504
(26.733)
(28.258)
17.701
6.243
(30.440)
(30.812)
134.818
79.187
(44.824)
(47.674)
84.109
107.903
(36.460)
(37.427)
27.085
0.499
(41.169)
(42.631)
64.346
94.554
(44.797)
(46.036)
point diff(t-1)
# Teams
# Seasons
n
0.371
(0.082)
32
5
160
Adj R^2
Controls
d
58.365
(33.170)
58.887
(42.761)
11.284
(39.454)
24.278
(36.057)
65.629
(57.186)
60.782
(53.166)
38.120
(54.668)
169.004
(57.934)
0.015
None
32
5
160
0.090
32
4
128
0.219
32
4
128
0.092
Other HG
HG
HG
proportions proportions proportions
Lag diff
1st Differenced No
No
No
Yes
position group (per team, per year)=homegrown/mercenary
HG=Homegrown: % of players on a team, drafted by that team
point diff=point differential
Table 2: Regression Estimates
Effect on log average tournament winnings
a
b
c
d
0.00438
(0.00168)
-0.00169
(0.00149)
0.00462
(0.00175)
-0.00112
(-0.00154)
Controls
None
Rank
Age
Age and Rank
Adjusted
R^2
0.0439
0.443
0.0951
0.464
Coefficient
estimate for
Saved Break
Points
This table shows the coefficient estimates for a player’s total number of
saved breakpoints in a year when regressed on log of the player’s
average tournament winnings in dollars for the following year. The
different control variables are ATP year end ranking, expressed as a
non-linear indicator variable with 4 groups, and the player’s age,
expressed as a non-linear indicator variable with 3 groups.
Table 2
Coef.
S.E.
totalcredit
(response)
(response)
Variables
annualincome employment creditaccounts bankruptcies debttoincome
0.15
371.84
1642.28
513279.66
25505.64
0.005
86.2
37.91
816.288
3644.61
totalcredit is the total amount of available credit measured in USD, annualincome is total
annual income measured in USD, employment is the amount of years of employment,
creditaccounts is the total number of credit accounts the person has, bankruptcies is the
total number of times a person has filed for bankruptcy, and debttoincome is the person’s
debt as a fraction of their income.
Coef.
S.E.
Controls
Adj. R^2
1
2
3
10795.96
1554.92
230.72
2526.513
2292.93
2254.82
None
creditaccounts creditaccounts All
bankruptcies
0.0017
0.1838
0.2114
4
25505.64
3644.61
0.2841
This table shows the effect the other variables have on the debttoincome variable. In
column 4 “All” refers to all other variables listed above.
Table 2: Regression Estimates
Effect on Inflation Rate
Coefficient
estimate
Controls
A
-0.0168
(0.007)
None
B
-0.0175
(0.007)
Investment Ratio
Adjusted R2
Year
Observations
0.0280
2014
165
0.0292
2014
165
C
0.0011
(0.005)
Investment Ratio
& Literacy Rate
0.5421
2014
165
D
0.0028
(0.004)
All
0.6986
2014
165
This table contains the information of estimating the effect on “Inflation Rate” based on
different control variables. All of the data are from 2014, and there are total 165
observations. “All” includes “Investment Ratio”, “Literacy Rate” and “Life Expectancy”.
The Adj. R2 for column D is 0.6986, bigger than the value in column C, which is
considered as a better model. We can expect that “Life Expectancy” has a strong, positive
relationship with the dependent variable, ln(GDPpc).
Effect on Log (Average annual working hours Female)
a
b
c
d
Coefficient estimate
0.0238655
0.0176315
0.0180924
0.018539
(standard error)
(0.0060768)
(0.0121407)
(0.0120469)
(0.0121657)
t
3.93
1.45
1.50
1.52
Controls
None
Only regress on Average
Marriage age of Male
Average Marriage age of
Male
Average Marriage age of
Male and Fertility Rate
All
Average Marriage age of
Male and Fertility Rate and
Education Level
observations
55
55
55
55
2
Adjusted R
0.2108
0.3719
0.3820
0.3730
Estimates of this model used national data of 55 countries. Standard errors are cluster robust around each panel (Annual Working HrsMarriage Age of Female).
Column (a) shows the effect of Average marriage age of female on Annual working hours. Column (d) shows the regression when controlling the effects of Average
Marriage age of Male, Fertility Rate and Education Level on our independent variables. The emphasis in these tables is on the source of Annual working hours and
Marriage age of females. This supports the hypothesis that, one year older for the marriage age of female will lead to 1.8539% change on annual working hours
supplied per female, controlling all other factors.
1
Estimates of model using government data to determine the effects of the amount of poverty on
gun-violence. Data collected on county level in the United States, except for state-wide gun laws
(i.e. permits). The various control variables represented: lawpc is the number of full-time
employed law enforcement officials per county, lawpcsquared is “lawpc” squared, permit is an
indicator variable of whether or not the state the county is located in requires some form of
permit for purchase of a handgun, and lastly, lpop, which is the natural log of the population
density in each county. “All” includes all four mentioned controls. The coefficient estimate
remains very significant as additional controls were added, and improved the overall accounting
of variation.
ECON 360: Econometrics.
: Purdue University.
Table 2: Regression Estimates
Effect on Number of Fast Food Restaurants
Median Household Income (β1)
Implied % Change
Housing Density (β2)
Implied % Change
Grocery Stores Per Capita (β3)
Implied % Change
Constant
Observations
Controls
Adjusted R2
1
.3491
(.0358)
34.9%
.0228
(.0083)
2.28%
-.0276
(.0099)
-2.76%
-11.25
(.3832)
2957
All
.0333
2
.3435
(.0354)
34.3%
.0050
(.0053)
0.5%
-11.19
(.3797)
2957
Housing Density
.0304
3
.3538
(.0358)
35.3%
4
.3466
(.0354)
34.6%
-.0066
(.0064)
-.66%
-11.27
(.3829)
2957
Grocery Stores
.0316
-11.21
(.3789)
2957
None
.0309
This model uses cross-sectional county based data from the 2013 Census. All variables are reported as natural logs.
Control ‘All’ refers to housing density and grocery stores per capita being controlled for in the regression. The emphasis
in this table is on the effect of median household income on the number of fast food restaurants. The results do not
support the hypothesis that median household income is positively related to the number of fast food restaurants.
Intercept
s.e
Yrs_SinceFinals
s.e
Model1
Model2
Model3
Model4
Model5
18243.96
1654.129
1772.591
1832.736
2282.452
235.53
749.2729
779.8518
806.3994
849.5323
-‐25.6603
6.356
Attend
s.e
-‐8.901658
3.127091
-‐9.003631
3.139585
-‐9.07386
3.15765
-‐8.520247
3.159465
176.0905
7.862874
173.0709
9.528582
173.9054
9.936636
170.3422
10.12902
322.2021
571.4479
361.7113
587.4731
-‐124.9011
658.2046
-‐2.16E-‐06
7.04E-‐06
-‐2.89E-‐06
7.02E-‐06
Win
s.e
Sal_Spent
s.e
Allstar
s.e
Adj. R^2
n
181.7705
113.1937
0.0931
0.793
0.7921
0.7908
0.793
150
150
150
150
150
Coefficient estimate β1 simple OLS (s.e.) β1 spec. b. (s.e.)
β1 c. (s.e.)
β1 d (s.e.)
β1 (gross)
17100000 (5725319 ) 11800000 (4113776 ) 21600000 (5616624) 12900000 (4405705 )
Controls
None
Budget
Film Genre
All
Adjusted R2
0.0524
0.5166
0.1742
0.513
Gross is the total revenue in U.S. dollars a film garnered at the box office. Budget is the film’s budget in U.S.
dollars. Film Genre is the genre of each film included in the data, and includes: Adventure, Action, Comedy,
Documentary, Drama, Horror, Romantic Comedy, Thriller/Suspense, and Western.
Econ 360 project data table 2
variable name type
format
label
variable label
month
The total number of month of enrollment for each student upon graduation.
gpa
Accumulated gpa during college.
pocket
The amount of payment from student’s own pocket.
work
The total amount money earned from work and study during college.
scholarship
The total amount of scholarship or grants received during college.
tuition
Tuition and fees for a student who takes the same number of credits.
familyloan
Total amount of loan received from family members.
timeofloans
The number of times that student received loan from relatives or friends.
major
The students who have double major. Major = 1: one major.
credits
The number of credits needed to graduate.
Effect on longitude of graduation.(months)
1 Only
2Add
3Only
4All other
5 With
6 Full
GPA
Scholarshi
Scholarshi
means of
Major
model
p
p
support
and
Credits
GPA(B1)
-.064808
-.0816965
NA
NA
NA
-.1153693
1
(.1258316
(.12627)
(.127266
)
T=-0.91
2)
Scholarship(B
NA
2)
-.0000862
-.0000849
NA
NA
-.0000765
( .000035
(.0000354
(.0000399
5)
)
)
T=-1.92
Tuition(B5)
NA
NA
NA
.0002067
NA
( .000268
.0000716
( .000267)
7)
Familyloan(B6
NA
NA
NA
)
-.0005742
NA
( .000982)
-.0003948
( .000527
9)
Timesofloan(B
NA
NA
NA
7)
Major(B8)
NA
NA
NA
-1.163051
NA
-1.233999
(1.603061
(1.567671
)
)
NA
4.50453
1: one major,
4.839546
(1.720534
0:two major
(1.66365)
)
T=2.62
Credits(B9)
NA
NA
NA
NA
-.001331
-.0030398
8
(.0157617
(.015401
)
7)
Pocket(B2)
Work(B3)
NA
NA
NA
NA
NA
NA
-.0005057
NA
-.000168
(.0009916
(.0009788
)
)
-.0003322
NA
.0000406
( .000599
(.0006528
9)
)
Test of
t=-0.51
T=-2.4
None of
Major:
Two
significant
Pr=
Pr=0.017
the X has
T=2.91
variables
t value
Pr=
are
greater
0.004
significant.
0.611
than 1.
Major and
scholarshi
p.
R^2
0.0014
0.0319
0.0297
0.0131
0.0433
0.0772
Adjusted R^2
-0.0039
0.0216
0.0246
-0.0137
0.0331
0.0310
Effect on Sleep Hours
Model
a
b
c
d
Coefficient
estimate
-0.322
-0.322
-0.1667947
-0.1727768
Standard error 0.0180234
0.0163025
0.0366734
0.0361425
t
-17.87
-19.75
-4.55
-4.78
Control
None
Gender
Obsercation
72
72
Gender and
working
hours
72
All
Gender,working
hours, and year
72
Adjusted R^2
0.8176
0.8507
0.8845
0.8887
*Model
a. Sleep Hours = 𝛽𝛽0 + 𝛽𝛽1(Education)
The data of sleep hour are average hours among people, the proportion of genders are
different so that data are not gender weighted ones which might cause bias.
b. Sleep Hours = 𝛽𝛽0 + 𝛽𝛽1(Education) + 𝛽𝛽2(Gender)
As gender is dealt as binary data so that the coefficient of Education doesn’t change.
c. Sleep Hours = 𝛽𝛽0 + 𝛽𝛽1(Education) + 𝛽𝛽2(Gender) + 𝛽𝛽3(Working Hours)
Similar with Model a, the data of working hours are based on average working hours
among people, which may cause bias.
d. Sleep Hours = 𝛽𝛽0 + 𝛽𝛽1(Education) + 𝛽𝛽2(Gender) + 𝛽𝛽3(Working Hours) + 𝛽𝛽4(Year)
As years in which the data were collected are different, the proportion of genders
might change as time goes by, which can cause bias.
* Definition
Sleep Hours: The average sleep hours in a day of people over 25 in the same education level and
same gender in the US in different years, which is measured in hours with two decimals.
Education: Educational attainment of people in US. There are four categories which are “less
than a high school diploma”, “high school graduate bur no college”, “some college or associate
degree”, and “bachelor degree and higher”. And 1 to 4 are used to represent education level from
low to high. (e.g.: 1 represent a less than high school diploma)
Gender: Male or Female. 0 represents male and 1 represents female.
Working Hours: Average hours spent in a day by people over 25 on working and working
related activities in the same education level, same gender in the US in different year, which is
measure in hours with two decimals.
Year: The year in which data was collected. The years I choose is from 2006 to 2014.
Table 2: Regression Estimates:
Effect on the Ranking Level for the University
A
B
C
D
E
Coefficient
estimate
-0.0131
(0.0024)
-0.0176
(0.0027)
-0.0191
(0.0029)
-0.0199
(0.0029)
-0.0241
(0.0034)
Controls
None
Tuition
Tuition &
Mid-Salary
All
Adjusted 𝑅2
0.2190
0.2833
0.2862
Tuition, MidSalary &
Location
0.3251
0.3490
Year
2014
2014
2014
2014
2014
Observations
108
108
108
108
108
This table contains the results of estimating the effect of the amount of international
applications to a university. Totally 108 data are from 2014. “All” means the
variables—tuition, mid-salary, location and SAT requirement—are all be controlled
in Model E. Comparing the adjusted 𝑅 2 s, Model E is the batter model. In addition,
based on the results of coefficient estimates, the university’s ranking level has a
negative effect on the amount of the international applications to the university.
Section 1: Summary
People argue that employees with higher education, whether the person is male or female,
the ethnicity of the worker have a huge effect on wage rates. The non-binary dependent variable (y)
in this economic scenario is wage; (y= a + log(x), where x= 1,2,3 …). This is because the wage is
affected by other independent variables, including education and experience. Thus, it depicts the
total monthly earnings of an employee in preferred currencies and is in quantitative form.
Thus;
y=f (x1 + x2 + x3 +…)
That is;
y = wage = f (education, age, sex, ethnicity).
The “x” that will be the focus for the task’s casual analysis will be education. This
independent variable has a vast effect on the dependent variable y in the regression expression. It is
the paper’s casual analysis since it exhibits a fascinating relationship. Notably, education,
experience, sex and ethnicity show interesting outcomes whenever correlated with the non-binary
dependent variable. Indeed, a change in one of the independent variables will significantly affect the
results for the dependent variable. This relationship vastly interests the student because all the
independent variables contribute to the outcome of the dependent variable. Students and individuals
looking for job opportunities must understand and embrace the relationship since it will affect how
much they earn every week. Those with higher education and vast experience in the job market will
earn more than those with low education and less work experience. Besides, the unit of observation
for gathering relevant information would be in the job market, particularly in the workplace. The
row in the data set comprises the observations of the relevant data for analysis.
Section 2: FAQs
1. What is the causal relationship of interest?
The above regression equation has a causal relationship of interest, considering the effects of
the independent variables on the dependent variable. Ideally, a change in an independent variable
will cause a change in the dependent variable. For instance, an employee with high education, vast
work experience, being male and being white will earn a high weekly salary. This implies that high
education, extensive work experience, being male and being white cause employees to earn a lot of
money. Such a causal relationship makes it possible for people willing to seek job opportunities to
get an education and gain work experience to receive well-paying jobs. Individuals without these
qualifications will receive low salaries at the end of each week. High education, vast work
experience, age, sex, and ethnicity are attributable to increased productivity, profitability, and
competitiveness in the employment sector. Thus, employees with these fundamentals are preferred
most in all organizations.
2. What would be the ideal controlled experiment to test #1?)
Randomized controlled experiment is the ideal technique for testing the causal relationship
of interest. Indeed, after randomly selecting a given variable (education), it will be possible to hold
the other variables constant and determine its relationship with the dependent variable. The
controlled experiment will show how one variable (independent variable) in a data set has a direct
impact on another variable (dependent variable).
Fall 2022 – Page 1
Economics 360 Data Analysis Project
For this project, students will apply the methods from class to a real set of data. Below are the
milestones at which students are expected to have tangible progress towards completion.
Critical Due Dates:
September 25, 2022: Summary of topic and first 2 FAQs due.
October 30, 2022: Due date to present data set (video) and “working” regression model.
November 20, 2022: Formatted Table 2 due.
December 9, 2022: Final project due.
1. Pose a question. What interests you? Your data set and hypotheses do not have to have
obvious Economics overtones, so if you want to study sports or entertainment, that’s okay. Just
make sure you can find data on the topic of interest. For example:
• Your friend says that “for clothing brands, being featured prominently in popular movies has
a huge effect on the sales of the brand.” What is the causal relationship of interest? Sales
revenue is increased (caused) by the brand’s visibility in movies, ceteris paribus. You
should be able to find data on the sales of various clothing brands and the timing and
popularity of movies in which they were featured. If you find significantly higher sales for
brands after the movies are released, you can go back to your friend and say, “Aha! You
don’t know diddily about the fashion industry, and I’ve got the data to prove it!”
Think of some claim that has been made in one of your other classes or by a friend/coworker/family member that you want to test with data. Then find a sample that contains
observations you can use to test the claim. A good question is: a) specific, b) capable of being
answered empirically, and c) interesting (non-obvious, non-trivial, original).
By Sunday September 25, students must have an approved 1 page summary of their topic and
responses to the first 2 FAQs (from Angrist and Pischke, first day of class). The summary must
include:
• A non-binary dependent variable (y), 1
• A line like the next one, (as exhaustively as possible) listing variables that “explain”
variation in y:
𝑦𝑦 ≡ 𝑤𝑤𝑤𝑤𝑤𝑤𝑤𝑤 = 𝑓𝑓(𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒, 𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒𝑒, 𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖 𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎, 𝑗𝑗𝑜𝑜𝑜𝑜 𝑎𝑎𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡𝑡 … ),
• The “x” that will be the focus of the paper’s causal analysis, and a compelling explanation
why this relationship interests the student,
• The unit of observation, e.g., individuals, countries, football teams. In the data set, what will
the rows consist of? 2
This is scored pass/fail and counts toward the final score (see last page) on the project. Do not
to wait until the last day to submit your proposal unless you are very confident everything is
in order. We can go through as many rounds of revision as needed before the due date, so if you
want to make sure your idea is both feasible and suitable for this assignment, consult the
1
It is strongly preferred that you have a ratio level dependent variable like wage, price, population, etc., because
regression is better suited to analyzing these.
2
The 50 United States are a poor choice for the sample. They are small in number and much more heterogeneous
within than across. The instructor will not approve proposals to use States as the unit of observation.
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 2
instructor ahead of time. There will be no revisions for credit allowed after the due date.
This includes proposals submitted on time and rejected ex post.
2. Data collection. Go find data! Data are all around you, waiting to be organized and analyzed.
All one has to do is observe the phenomenon of interest and systematically record observations.
Where can you go to observe the “x” and “y” variables in the causal relationship of interest?
End Goal:
• Data consist of observations (rows) and variables (columns) and have a rectangular
“spreadsheet” layout. A data set must observe multiple variables for multiple (n) elements.
• I’m not asking you to formulate your own survey or anything like that; if you’re really
ambitious, you can certainly do it, but there are plenty of suitable sample data sets already
collected that you can use (see Data and Writing Resources in D2L).
• You need enough information to make meaningful statistical inferences, i.e., large enough
sample size and variation in your variables. E.g., it would be hard to infer much about a
small Indiana town that enacts a zoning regulation, based on a comparison with 5
neighboring towns that didn’t (𝑛𝑛 = 6 and 𝑥𝑥 = 1 for only 1 observation!).
Where should you look?
• Research librarians, Profs. Zoe Mayhook and Bert Chapman, have built the “Costco” of
economic data (http://guides.lib.purdue.edu/Econ360) for our class. For most topics, you
will be able to find a source of data using one of the tools on this page.
• Don’t worry if you have to go to multiple sources for different variables, e.g., the
unemployment rate across counties from bls.gov, and the murder rate from the FBI. Consult
Ben and/or his lab instructions for how to match them to one another in Stata. It requires a
little patience, but is relatively painless and makes your data set much more powerful.
• If you have difficulty deciding on a set of data or finding a set that you can use to test your
hypotheses, please consult me, and I will help get you going.
Students will submit a video presenting the following, due October 30:
• “Working” regression specification,
• Data set in Stata format, and
• Codebook, e.g., Word document, explaining variable definitions.
“Present” means a 5-10 minute demonstration in which you open the data set, explain what
variables and observations you have, and answer a couple practical questions that will help make
the rest of the project easier. This is scored “pass” (full), “low pass” (½), or “fail” (0) and counts
toward the grade on the project (see last page). Note: an approved project topic is a
prerequisite for this video, even for students that do not meet the topic approval due date.
The University has its own version of YouTube called “Kaltura,” that students should use to
record their voice and capture their screen to make this video. Specifically the feature is called
Kaltura Capture (see the Data Set Assignment in Brightspace for a brief tutorial in how to use
it). After recording your video, Capture will upload it to the University’s server and create a
URL. You should submit this URL to earn credit for this milestone in the Project.
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 3
3. Econometric Analysis. Students will document all of the following in a word-processed
report and submit it on the last day of class. All tables and figures should be “self-contained” by
including a caption and intuitive labels for the rows, columns and axes.
3a. Give a sense of how your variables are distributed. Your write-up should include a
professional and easily understandable table of the descriptive statistics on your variables. This
means sample size, sample mean, a measure of variability such as standard deviation, and
skewness. For categorical or binary variables, make it clear how you have made them
quantitative and that the means represent proportions, e.g., the proportion that is male, lives in
Tippecanoe county, or the proportion of the songs on your streaming history that is a particular
genre. Ask yourself, “Do all the descriptive statistics seem plausible? If they do not, what are
some explanations for their bias?”
In the write-up:
• Label it “Table 1: Descriptive Statistics.”
• Carefully explain the units (weekly income? monthly? annual?) in the row labels and the
unit of observation (county? state? occupation-state?) in the caption.
• Are there missing observations or outliers for any variables? If so offer an explanation.
• Does the size of your sample present any concerns about the normality of the sampling
distribution? Speculate about whether the dependent variable’s distribution (skewness,
outliers) presents any problems for the Central Limit Theorem.
o Would taking logs help? 3 For clarity present the descriptive statistics in levels, even if
you take logs when you do the regression.
3b. Use Stata to estimate a simple linear regression for the relationship between the
(hypothesized) causally related variables:
𝑦𝑦� = 𝛽𝛽̂0 + 𝛽𝛽̂1 𝑥𝑥.
Use Stata to produce a scatterplot showing the mapping of x to y, and include the estimated
regression line on the plot to summarize their co-movement. 4
In the write-up:
• State the null and alternative hypotheses in terms of parameters (𝛽𝛽s) that will test the
relationship of interest.
• Discuss the sign (+/-) on 𝛽𝛽̂1? Does it confirm your original prediction?
• Discuss the default and robust standard errors of 𝛽𝛽̂1 and how statistically different from the
null (usually but not always zero) hypothesized value the estimate is. In practical terms, is
there a “wide” confidence interval around the point estimate?
• In terms a non-economist could understand, interpret the coefficient estimate: “. . . a one unit
change in . . . is associated with a . . . .” Is this a practically large effect?
• Discuss how well the linear trend “fits” the data. What is the coefficient of determination
(𝑅𝑅 2 )?
3
I recommend, before proceeding to write up your results from 3 b-e, that students get their functional specifications
(especially of y) right: logs or levels, scaling by 1000 or 1/1000.
4
This page on the Stata website will help with the syntax for making the scatterplot:
https://www.stata.com/support/faqs/graphics/gph/stata-graphs/. If you have a binary x variable: your scatterplot
will just look like “goal posts;” talk to Ben about substituting a table of t test results for the difference in means.
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 4
3c. Robustness part I. Build up your regression specification with explanatory variables that
either: i) shrink the error variance and improve precision of the estimates, or ii) control for
omitted factors in the error term (in the simple OLS specification). Create a table like the one in
Ben’s lecture notes, showing between 4 and 6 different specifications (1 estimate per column)
and enabling the reader to compare the 𝛽𝛽̂ s of interest by reading across one row.
The lower portion of the table should have a row that enables the reader to differentiate the
estimates according to what else is included in the model, like the example below. By
November 20, a polished (full points) version of “Table 2” is due in the drop box on
Brightspace. This counts toward your grade on the project (see last page). An incomplete or
poorly formatted Table will earn a “low pass” (½) or “fail” (zero points) on this part, which
signals that the student needs to revise it before the final due date.
Table 2: Label this one “Table 2: Regression Estimates” in your Write-Up
Your
main x
variable
with
units
Controls
a
b
c
d
�
̂
̂
�Simple OLS β1 � �Your 𝛽𝛽1|spec. 𝑏𝑏 � �Your 𝛽𝛽1|𝑐𝑐 � �Your 𝛽𝛽̂1|𝑑𝑑 �
(𝑠𝑠. 𝑒𝑒. )
(𝑠𝑠. 𝑒𝑒. )
(𝑠𝑠. 𝑒𝑒. )
(𝑠𝑠. 𝑒𝑒. )
None
[Important
control var.]
[More
control
vars.]
All
Adjusted
𝑅𝑅 2
The body of the table should be as self-explanatory as possible, but any information that cannot
go in the row labels, etc., should be explained in a caption, e.g., what is included in “All”?
In the write-up:
• Devote at least 1 paragraph (each) to discussing variables in the error term that could create
omitted variable bias. State specifically what in the error term (think education and omitted
ability) is related to x (and why, theoretically, you should worry about this) and whether it
would bias 𝛽𝛽̂ upward or downward. Do this for 2 different potential sources of bias.
o This might seem challenging if you haven’t taken a lot of other Econ. theory classes, but
consult your instructor or TA about your ideas.
• Discuss the set of estimates. How does 𝛽𝛽̂ change with the addition of controls? Is this
consistent with controlling for omitted variables and reducing bias (see above)?
• Comment on what’s going on with 𝑅𝑅� 2 and standard errors as you add controls.
• Assess your level of satisfaction with how the multiple regression tackles omitted variable
bias.
o It’s okay if you are critical. Often the omitted factors are very difficult to observe and
control for in cross sectional samples.
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 5
3d. Robustness part II. Extend your causal hypothesis to groups within the sample. For
example: “stricter parental ratings will have a negative effect on video game sales. But it will
have a bigger negative effect on ‘first person shooter’ style video games.” Report on a table the
results of a specification that involves interacting the x variable of interest with 1 or more other
regressors. Report the marginal effect of x for each group separately and a standard error for it.
Label this one “Table 3: Interaction Estimates”.
In the write-up:
• Explain why you think this interaction is a relevant test of the robustness of your hypothesis.
“Why should 1st person shooters be more adversely affected by ratings guidelines?” “Oh
yeah, because they tend to be more violent than other genres of games.”
• Does the group with the biggest (absolute value) effect match your hypothesis?
• Are the marginal effects statistically different between/among multiple groups? State a null
hypothesis, test it to verify this, and report the results.
3e. Diagnostics. Run the B-P and White tests for heteroskedasticity and report the results. They
don’t necessarily have to be on a table, because the code will be in your do file. Report (and
explain in the caption) on the table in part (c) robust standard errors if warranted.
Run the RESET to detect functional form misspecification. Your most saturated specification in
part (3c) should include polynomial and interactions terms that, if omitted, would significantly
reduce 𝑅𝑅 2 . Your do file and your summary of the results should include F statistics to confirm
the joint significance of these regressors.
Produce and include in the write-up the leverage-residuals plot from the full-sample specification
with the highest adjusted R squared. Are there any outliers or influential observations that
concern you? If so your tables in parts (b-d) should probably exclude this observation and
contain a note in the caption explaining your treatment of outliers. If you decide that the
observation(s) should be in the sample, explain your reasoning in the caption.
4. Overall instructions for the write-up. Organize your written summary as follows.
• Roughly 1 page containing: a statement of the causal relationship of interest, answers to the
first 2 FAQs, and a summary of the (observational) data source you use to answer FAQ #3.
• Roughly 1 page containing: the regression model specification in equation form and a
written explanation of the variables you will use in your analysis and the units, e.g.,
individuals or countries, that are observed. This is where you state hypotheses about
parameters you will test, too.
• The descriptive stats table and supporting text. Depending on the size, about 1 page.
• A figure containing the 2-D scatterplot and simple OLS line.
• The multiple regression tables (simple OLS as 1st column) and supporting text, statistics, and
diagnostics.
• A brief summary of your results. Have you accurately measured the causal relationship of
interest? Again it’s okay if you’re skeptical.
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 6
o What kind of “natural experiment” 5 would you seek out if you could spend another
semester (doesn’t that sound fun?) studying this and improving your methods?
As a minimum for a good grade, the caliber of written communication will befit a college
graduate. A paper that is incomprehensible (because of poor sentence structure, grammar, using
words out of context, or subject-verb disagreement, et al.) will earn you no points. I will not (nor
will any reader) waste time trying to decipher poorly written paragraphs. I have to read over 50
papers from the class, and I reserve the right to award a failing grade to any paper that is too
hard to read for grammatical or mechanical reasons.
• If you are concerned about your writing ability, visit the writing center. 6 Get a friend,
sibling, or co-worker to read your paper and proofread it. Run spellcheck (!) and search your
paper for incorrect homonyms (spellcheck won’t find these). Do whatever it takes to avoid
handing in a poorly written paper.
• Cite any sources, including data, in the text, (Author year) and include a works cited page.
• Use active voice.
• Avoid the following phrases: “I think”, “I believe”, “I feel.” You’re writing the thing; you
wouldn’t be writing it if you didn’t think it.
• Double space your text.
• Do all the other good things you learned in English composition classes.
Remember it’s your job to communicate your thoughts to the reader—not the reader’s job
to divine what you are trying to say.
On (or before!) December 10, students will turn in the following, by uploading 3 files to the
Semester Project folder on Brightspace.
1. The 7-8 page (including tables and figures) write-up of the project. Has its own folder on
D2L and checks for plagiarism; upload in Word (.doc or .docx) or .pdf format.
2. The (cleaned, .dta format) data set you used to produce the results.
3. The Stata do file containing the commands, in the order they appear in your write-up, that you
used to produce the regression estimates, test hypotheses, and run other tests. I should be able to
open the data set in Stata and run your do file from start to finish without any errors and reproduce your results.
#s 2 and 3 go in the same folder, which allows multiple files per student.
5
An event that is exogenous to the individuals and induces randomness in the x variable of interest. E.g., some
people live in states that pass laws banning electronic “e-cigs” cigarettes; this alters their calculus of whether to use
e-cigs, tobacco cigarettes, or none at all, in a way that has nothing to do with their individual preferences. So some
people who would likely continue using e-cigs are induced to stop and can be compared to people in other states that
are left to their preferences.
6
http://owl.english.purdue.edu/writinglab/servicesoverview
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 7
Project Grading Rubric
The instructor evaluates students’ papers on the following criteria. Each criterion will
receive a “pass,” “low pass,” or “fail” (0 points) score, (see next page).
1. Introduction (Pass=5; Low Pass=3):
a. Describes a novel and interesting empirical question
b. Adequately addresses the first 2 “FAQs” in empirical analysis
c. Clearly explains the data source and unit of observation
2. Description of methods (Pass=5; Low Pass=3):
a. Includes a regression model with the exhaustive list of controls
b. Clearly explains the variables and units in the model
c. Clearly states hypotheses that will be tested statistically
3. Tables and figures (Pass=5; Low Pass=3):
a. All assigned parts are present
b. Are well-labeled, well-formatted, easy-to-read, e.g., no log variables on T1
c. Are self-contained with informative captions
4. Empirical methods/results are (Pass=5; Low Pass=3):
a. Correct and applied consistently with in-class examples, e.g., using log forms
of variables
b. Supported by appropriate testing
c. Accompanied by Stata code, enabling the reader to reproduce the findings
5. Conclusion(s) drawn (Pass=5; Low Pass=3):
a. Explained clearly and concisely in text form
b. Are consistent with the quantitative results and principles of statistical
inference studied in class
c. Include the practical significance of the results, e.g., elasticity of y with respect
to x, when using a log-log model
6. Data set (Pass=5; Low Pass=3):
a. Unit of observation, set of variables match those specified in approved topic
proposal and requested by the instructor.
b. Has value added, e.g., intuitive variable names and/or labels, redundant
variables dropped, nonnumeric characters (like %) removed
c. Is cited and enables the reader to locate its original source(s)
7. Written communication (only “pass” or “fail”):
a. Is coherently organized (as described in the instructions)
b. Transitions from each idea to next smoothly
c. Contains minimal proofreading/formatting/grammatical errors
d. Data and empirical results/methods are described in comprehensible language
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Fall 2022 – Page 8
Item(s)
Score
1[7“Pass”] ×
1&2
3-6
1 page proposal (approved by
9/25/22)
/2
Data set presentation (by 10/30/22)
/4
Table 2 (by 11/20/22)
/4
Overall Score
/10
/20
/10
/40
Overall Score = 1[Item 7 “Pass”](Score, Items 1&2) + (Score, Items 3 − 6)
+ (Points on intermediate steps)
ECON 360: Econometrics. Ben Van Kammen: Purdue University.
Essay Writing Service Features
Our Experience
No matter how complex your assignment is, we can find the right professional for your specific task. Achiever Papers is an essay writing company that hires only the smartest minds to help you with your projects. Our expertise allows us to provide students with high-quality academic writing, editing & proofreading services.
Free Features
Free revision policy
$10Free bibliography & reference
$8Free title page
$8Free formatting
$8How Our Dissertation Writing Service Works
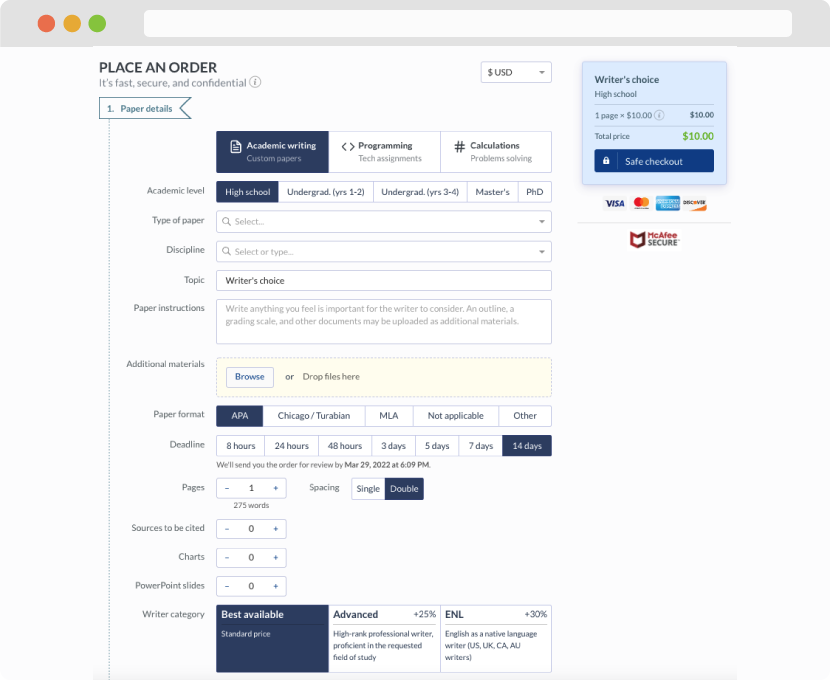
First, you will need to complete an order form. It's not difficult but, if anything is unclear, you may always chat with us so that we can guide you through it. On the order form, you will need to include some basic information concerning your order: subject, topic, number of pages, etc. We also encourage our clients to upload any relevant information or sources that will help.
Complete the order form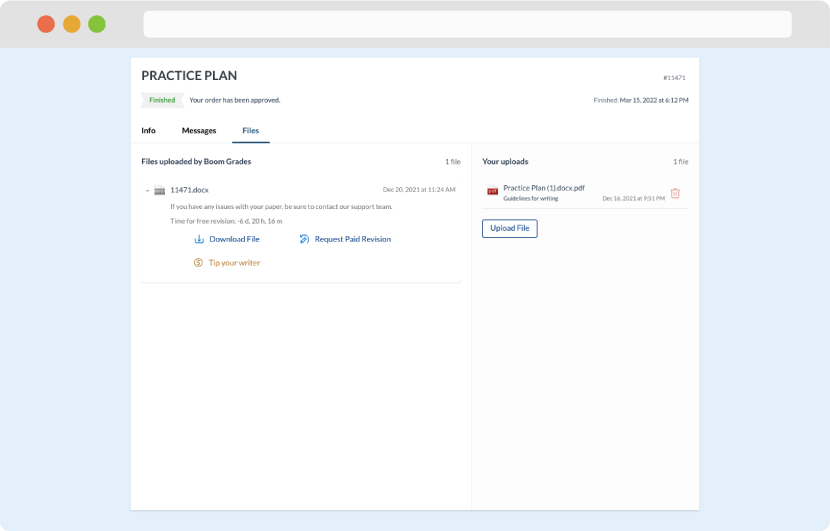
Once we have all the information and instructions that we need, we select the most suitable writer for your assignment. While everything seems to be clear, the writer, who has complete knowledge of the subject, may need clarification from you. It is at that point that you would receive a call or email from us.
Writer’s assignment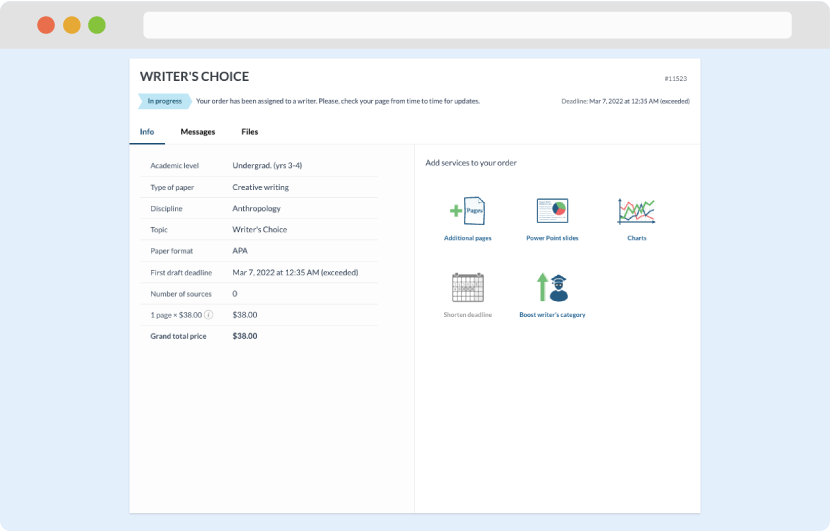
As soon as the writer has finished, it will be delivered both to the website and to your email address so that you will not miss it. If your deadline is close at hand, we will place a call to you to make sure that you receive the paper on time.
Completing the order and download