Check chapter 4 & 5
• Week
6
• Physical Database Design and
Performance
• Chapter 5
Objectives
• Define terms
• Describe the physical database design process
• Choose storage formats for attributes
• Select appropriate file organizations
• Describe three types of file organization
• Describe indexes and their appropriate use
• Translate a database model into efficient structures
• Know when and how to use denormalization
2
Physical Database Design
• Purpose–translate the logical design of data into the technical
specifications for storing and retrieving data.
• Goal–create a design for storing data that will provide adequate
performance and ensure database integrity, security, and
recoverability.
3
Physical Database Design
4
Logical Physical
Physical Design Process
5
Normalized relations
Volume estimates
Attribute definitions
Response time expectations
Data security needs
Backup/recovery needs
Integrity expectations
DBMS technology used
Inputs
Attribute data types
Physical record descriptions (doesn’t
always match logical design)
File organizations
Indexes and database architectures
Query optimization
Leads to
Decisions
Figure 5-1 Composite usage map
(Pine Valley Furniture Company)
6
7
Figure 5-1 Composite usage map
(Pine Valley Furniture Company) (cont.)
Data volumes
Figure 5-1 Composite usage map
(Pine Valley Furniture Company) (cont.)
Access Frequencies (per
hour)
8
9
Figure 5-1 Composite usage map
(Pine Valley Furniture Company) (cont.)
Usage analysis:
14
,000 purchased parts accessed per
hour
8000 quotations accessed from these 140
purchased part accesses
7000 suppliers accessed from these 8000
quotation accesses
10
Figure 5-1 Composite usage map
(Pine Valley Furniture Company) (cont.)
Usage analysis:
7500 suppliers accessed per hour
4000 quotations accessed from these
7500 supplier accesses
4000 purchased parts accessed from
these 4000 quotation accesses
Designing Fields
•Field: smallest unit of
application data recognized by
system software
•Field design
• Choosing data type
• Coding, compression, encryption
• Controlling data integrity
11
Choosing Data Types
12
13
Figure 5-2 Example of a code look-up table
(Pine Valley Furniture Company)
Code saves space, but costs an
additional lookup to obtain actual
value
Field Data Integrity
• Default value –assumed value if no explicit value
• Range control –allowable value limitations
(constraints or validation rules)
• Null value control –allowing or prohibiting empty
fields
• Referential integrity –range control (and null value
allowances) for foreign-key to primary-key match-
ups
14
Handling Missing Data
• Substitute an estimate of
the missing value (e.g., using
a formula)
• Construct a report listing
missing values.
• In programs, ignore missing
data unless the value is
significant (sensitivity
testing)
15
Denormalization
• Transforming normalized relations into non-normalized physical record specifications
• Benefits:
• Can improve performance (speed) by reducing number of table lookups (i.e. reduce number of
necessary join queries)
• Costs (due to data duplication)
• Wasted storage space
• Data integrity/consistency threats
• Common denormalization opportunities
• One-to-one relationship (Fig. 5-3)
• Many-to-many relationship with non-key attributes (associative entity) (Fig. 5-4)
• Reference data (1:N relationship where 1-side has data not used in any other relationship) (Fig. 5-5)
16
17
Figure 5-3 A possible denormalization situation: two entities with one-to-one relationship
Figure 5-4 A possible denormalization situation: a many-to-many relationship with nonkey
attributes
Extra table access
required
Null description possible
18
19
Figure 5-5
A possible
denormalization situation:
reference data
Extra table access
required
Data duplication
Denormalize with caution
• Denormalization can
• Increase chance of errors and inconsistencies
• Reintroduce anomalies
• Force reprogramming when business rules change
• Perhaps other methods could be used to improve performance of joins
• Organization of tables in the database (file organization and clustering)
• Proper query design and optimization
20
Partitioning
• Horizontal Partitioning: Distributing the
rows of a logical relation into several
separate tables
• Useful for situations where different
users need access to different rows
• Three types: Key Range Partitioning,
Hash Partitioning, or Composite
Partitioning
• Vertical Partitioning: Distributing the
columns of a logical relation into several
separate physical tables
• Useful for situations where different
users need access to different columns
• The primary key must be repeated in
each file
• Combinations of Horizontal and Vertical 21
Partitioning pros and cons
• Advantages of Partitioning:
• Efficiency: Records used together are grouped together
• Local optimization: Each partition can be optimized for performance
• Security: data not relevant to users are segregated
• Recovery and uptime: smaller files take less time to back up
• Load balancing: Partitions stored on different disks, reduces contention
• Disadvantages of Partitioning:
• Inconsistent access speed: Slow retrievals across partitions
• Complexity: Non-transparent partitioning
• Extra space or update time: Duplicate data; access from multiple partitions
22
Designing Physical database Files
• Physical File:
• A named portion of secondary memory allocated
for the purpose of storing physical records
• Tablespace–named logical storage unit in which
data from multiple tables/views/objects can be
stored
• Tablespace components
• Segment – a table, index, or partition
• Extent –contiguous section of disk space
• Data block – smallest unit of storage
23
File Organizations
• Technique for physically arranging records of a file on
secondary storage
• Factors for selecting file organization:
• Fast data retrieval and throughput
• Efficient storage space utilization
• Protection from failure and data loss
• Minimizing need for reorganization
• Accommodating growth
• Security from unauthorized use
24
Indexed File Organizations
• Storage of records sequentially or nonsequentially with an index
that allows software to locate individual records
• Index: a table or other data structure used to determine in a file
the location of records that satisfy some condition
• Primary keys are automatically indexed
• Other fields or combinations of fields can also be indexed; these are
called secondary keys (or nonunique keys)
25
Rules for Using Indexes
1. Use on larger tables
2. Index the primary key of each table
3. Index search fields (fields frequently in WHERE clause)
4. Fields in SQL ORDER BY and GROUP BY commands
5. When there are >100 values but not when there are <30 values
26
Rules for Using Indexes
6. Avoid use of indexes for fields with long values; perhaps compress
values first
7. If key to index is used to determine location of record, use
surrogate (like sequence number) to allow even spread in storage
area
8. DBMS may have limit on number of indexes per table and number
of bytes per indexed field(s)
9. Be careful of indexing attributes with null values; many DBMSs
will not recognize null values in an index search
27
• Logical Database design and Relational
Model
• Chapter
4
Lesson Content:
• What is a ‘Relations’?
• What is a ‘Relational Model’?
• Component of a ‘Relational Model’?
• How Relations are different to E-R Diagram?
• Keys in Relations.
• What is integrity constraints?
• What is Referential Integrity?
• Mapping E-R diagram to Relational Models:
• Unary
• Binary
• Ternary
• Supertype/Subtypes
• Data Normalization: Form 1, Form 2, and Form
3
.
2
What is a Relations?
• A relation is a named, two-dimensional table of data.
• A table consists of rows (records) and columns (attribute or field).
• Requirements for a table to qualify as a relation:
• It must have a unique identifier (primary
key
).
• Every attribute value must be atomic (not multivalued, not composite).
• Every row must be unique (can’t have two rows with exactly the same values for all their fields).
• Attributes (columns) in tables must have unique names.
• The order of the columns must be irrelevant.
• The order of the rows must be irrelevant.
3
Correspondence with E-R Model
• Relations (tables) correspond with entity types.
• Rows correspond with entity instances.
• Columns correspond with attributes.
• NOTE: The word relation (in relational database) is NOT the same as the word
relations
hip (in E-R model).
4
Integrity Constraints
1. Entity Integrity
• No primary key attribute may be null. All primary key fields MUST have data.
2. Action Assertions
• Business rules (Recall from Chapter 3)
3. Domain Constraints
• Allowable values for an attribute (We shall see this clearly next)
5
6
1. Domain Constraints
Allowable values for an attribute.
Referential Integrity:
• Referential Integrity–rule states that any foreign key
value (on the relation of the many side) MUST match a
primary key value in the relation of the one side. (Or the
foreign key can be null)
• For example: Delete Rules
• Restrict–don’t allow delete of “parent” side if related rows exist in
“dependent” side
• Cascade–automatically delete “dependent” side rows that correspond
with the “parent” side row to be deleted
• Set-to-Null–set the foreign key in the dependent side to null if deleting
from the parent side not allowed for weak entities
7
8
Figure 4-5
Referential integrity constraints (Pine Valley Furniture)
Referential integrity
constraints are drawn via
arrows from dependent to
parent table
Transforming EER Diagrams into Relations
•Mapping Regular Entities to Relations
• Simple attributes: E-R attributes map directly onto the
relation
• Composite attributes: Use only their simple, component
attributes
• Multivalued Attribute: Becomes a separate relation with a
foreign key taken from the superior entity
9
(a) CUSTOMER entity
type with simple
attributes
Figure 4-8 Mapping a regular entity
(b) CUSTOMER relation
10
Transforming EER Diagrams into Relations (cont.)
•Mapping Binary Relationships
• One-to-Many–Primary key on the one side becomes
a foreign key on the many side
• Many-to-Many–Create a new relation with the
primary keys of the two entities as its primary key
• One-to-One–Primary key on mandatory side
becomes a foreign key on optional side
11
12
Figure 4-12 Example of mapping a 1:M
relationship
a) Relationship between customers and orders
Note the mandatory one
b) Mapping the relationship
Again, no null value in the foreign
key…this is because of the mandatory
minimum cardinality.
Foreign key
13
Figure 4-13 Example of mapping an M:N relationship
a) Completes relationship (M:N)
The Completes relationship will need to become a separate relation.
14
new
intersection
relation
Foreign key
Foreign key
Composite primary key
Figure 4-13 Example of mapping an M:N relationship (cont.)
b) Three resulting relations
Transforming EER Diagrams into Relations (cont.)
•Mapping Unary Relationships
• One-to-Many–Recursive foreign key in the same relation
• Many-to-Many–Two relations:
• One for the entity type
• One for an associative relation in which the primary key has
two attributes, both taken from the primary key of the entity
15
16
Figure 4-17 Mapping a unary 1:N relationship
(a) EMPLOYEE entity with
unary relationship
(b) EMPLOYEE
relation with
recursive foreign
key
17
Figure 4-
18
Mapping a unary M:N relationship
(a) Bill-of-materials
relationships (M:N)
(b) ITEM and
COMPONENT
relations
Transforming EER Diagrams into Relations (cont.)
•Mapping Ternary (and n-ary) Relationships
•One relation for each entity and one for the associative
entity
•Associative entity has foreign keys to each entity in the
relationship
18
19
Figure 4-19 Mapping a ternary relationship
a) PATIENT TREATMENT Ternary relationship with associative entity
20
b) Mapping the ternary relationship PATIENT TREATMENT
Remember that
the primary key
MUST be unique.
Figure 4-19 Mapping a ternary relationship (cont.)
This is why treatment
date and time are
included in the
composite primary
key.
But this makes a very
cumbersome key…
It would be better to create
a surrogate key like
Patient-Treatment#.
Transforming EER Diagrams into Relations (cont.)
• Mapping Supertype/Subtype
Relationships
• One relation for supertype and for
each subtype
• Supertype attributes (including
identifier and subtype discriminator)
go into supertype relation
• Subtype attributes go into each
subtype; primary key of supertype
relation also becomes primary key of
subtype relation
• 1:1 relationship established between
supertype and each subtype, with
supertype as primary table 21
22
Figure 4-21
Mapping supertype/subtype relationships to relations
These are implemented as one-to-one relationships.
Data Normalization
•Primarily a tool to validate and improve a logical design
so that it satisfies certain constraints that avoid
unnecessary duplication of data
• The process of decomposing relations with anomalies
to produce smaller, well-structured relations
23
Anomalies in this Table
• Insertion–can’t enter a new employee without having the employee take a class (or at least
empty fields of class information)
• Deletion–if we remove employee 140, we lose information about the existence of a Tax Acc
class
• Modification–giving a salary increase to employee 100 forces us to update multiple records
24
Why do these anomalies exist?
Because there are two themes (entity types) in this one relation. This results in data duplication and an
unnecessary dependency between the entities.
Data Normalization
• Primarily a tool to validate and
improve a logical design so that
it satisfies certain constraints
that avoid unnecessary
duplication of data
• The process of decomposing
relations with anomalies to
produce smaller, well-structured
relations
• When data does not look normal
we normalize it! 25
Well-Structured Relations
• Characteristics:
• A relation that contains minimal data redundancy and allows users to insert,
delete, and update rows without causing data inconsistencies
• Goal is to avoid anomalies
• Insertion Anomaly–adding new rows forces user to create duplicate data.
• Deletion Anomaly–deleting rows may cause a loss of data that would be needed for other
future rows (Remember referential integrity?).
• Modification Anomaly–changing data in a row forces changes to other rows because of
duplication.
26
General rule of thumb: A table should not connect to more than one entity type.
27
Table with multivalued attributes, not in 1st normal form
Note: This is NOT a relation.
28
Table with no multivalued attributes and unique
rows, in 1st normal form
Note: This is a relation, but not a well-structured one.
Notice that we have more than one table here.
Anomalies in this Table
Insertion–if new product is ordered for order 1007 of existing customer, customer data
must be re-entered, causing duplication
Deletion–if we delete the Dining Table from Order 1006, we lose information concerning
this item’s finish and price
Update–changing the price of product ID 4 requires update in multiple records
29
Why do these anomalies exist?
Because there are multiple themes (entity types) in one relation. This results in duplication and an
unnecessary dependency between the entities.
Second Normal Form
•1NF PLUS every non-key attribute is fully functionally
dependent on the ENTIRE primary key
• Every non-key attribute must be defined by the entire key, not
by only part of the key
• No partial functional dependencies
•What they mean: Split the tables so each table has
attributes related only to the primary key.
30
31
OrderID OrderDate, CustomerID, CustomerName, CustomerAddress
Therefore, NOT in 2nd Normal Form
CustomerID CustomerName, CustomerAddress
ProductID ProductDescription, ProductFinish, ProductStandardPrice
OrderID, ProductID OrderQuantity
Figure 4-27 Functional dependency diagram for INVOICE
32
Partial dependencies are removed, but there are still transitive dependencies.
– Transitive dependency means: find tables within tables.
– Clever students do sometimes find these tables from the first attempt so they
move from F2 to F3 immediately.
Getting it into Second Normal
Form
Figure 4-28 Removing partial dependencies
Third Normal Form
• 2NF PLUS no transitive dependencies (functional dependencies on
non-primary-key attributes)
• Note: This is called transitive, because the primary key is a determinant for
another attribute, which in turn is a determinant for a third
• Solution: Non-key determinant with transitive dependencies go into a new
table; non-key determinant becomes primary key in the new table and stays
as foreign key in the old table
33
34
Transitive dependencies are removed.
Figure 4-29 Removing partial dependencies
Getting it into Third
Normal Form
Essay Writing Service Features
Our Experience
No matter how complex your assignment is, we can find the right professional for your specific task. Achiever Papers is an essay writing company that hires only the smartest minds to help you with your projects. Our expertise allows us to provide students with high-quality academic writing, editing & proofreading services.
Free Features
Free revision policy
$10Free bibliography & reference
$8Free title page
$8Free formatting
$8How Our Dissertation Writing Service Works
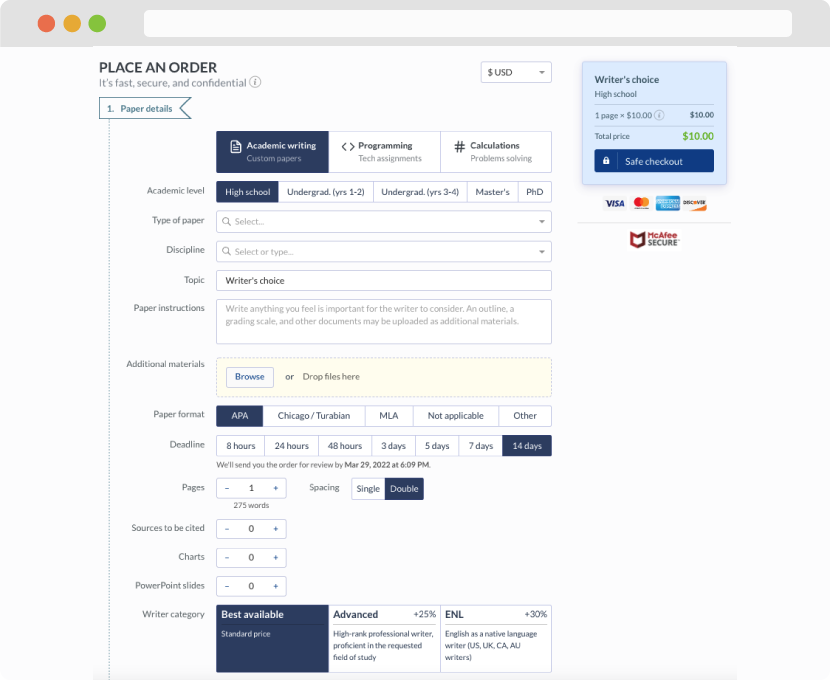
First, you will need to complete an order form. It's not difficult but, if anything is unclear, you may always chat with us so that we can guide you through it. On the order form, you will need to include some basic information concerning your order: subject, topic, number of pages, etc. We also encourage our clients to upload any relevant information or sources that will help.
Complete the order form
Once we have all the information and instructions that we need, we select the most suitable writer for your assignment. While everything seems to be clear, the writer, who has complete knowledge of the subject, may need clarification from you. It is at that point that you would receive a call or email from us.
Writer’s assignment
As soon as the writer has finished, it will be delivered both to the website and to your email address so that you will not miss it. If your deadline is close at hand, we will place a call to you to make sure that you receive the paper on time.
Completing the order and download