SchoolValley
Bayside
Valley
Valley
Bayside
Valley
Bayside
Bayside
Valley
Bayside
Valley
Valley
Valley
Valley
Bayside
Valley
Valley
Valley
Bayside
Bayside
Bayside
Bayside
Bayside
Bayside
Valley
Bayside
Bayside
Bayside
Valley
Valley
Bayside
Valley
Valley
Bayside
Bayside
Bayside
Valley
Valley
SAT Score
1060
1135
1160
1260
1275
1355
1390
1400
1410
1450
1490
1520
1525
1550
1560
1585
1610
1645
1650
1685
1700
1720
1740
1755
1770
1790
1800
1880
1900
1915
1940
1990
2040
2050
2080
2190
2300
2000
City
Albuquerque
Atlanta
Baltimore
Birmingham
Boston
Charlotte
Chicago
Cincinnati
Cleveland
Columbus
Dallas
Denver
Detroit
El Paso
Frankfurt
Fresno
Galveston
Greenville
Harrisburg
Indianapolis
Jacksonville
Kansas City
Las Vegas
Los Angeles
Louisville
Memphis
Miami
Milwaukee
Minneapolis
New Orleans
New York
Oklahoma City
Orlando
Philadelphia
Phoenix
Pittsburgh
Portland
Providence
Richmond
Sacramento
Salt Lake City
San Antonio
San Diego
San Francisco
Time (minutes)
22.4
29.0
33.1
20.8
34.5
25.8
39.5
27.6
29.1
24.4
27.5
29.0
31.1
23.2
22.4
24.1
21.2
21.1
20.8
29.8
26.5
24.4
28.6
37.4
22.2
26.5
31.6
24.8
24.6
33.3
44.5
21.9
26.4
35.5
27.2
26.6
26.4
25.5
28.5
26.6
21.1
23.3
25.5
34.4
Seattle
Springfield
St. Louis
Tucson
Tulsa
Washington, D.C.
29.8
19.4
28.5
26.4
20.0
36.5
Tub Sales ($) College Degree (1 = Yes)
107000
1
87300
0
103000
1
97700
1
111600
1
95700
0
91200
0
119600
1
94200
0
91300
1
88700
0
109700
1
110400
0
90800
0
118300
1
91500
0
88800
0
97400
1
71800
0
106900
1
These data are a random sample of the sales performances (in
sales force, along with data on the level of educational attain
There is no data for this question.
Follow the directions on the take-home…
You might use “text” format and a list like
–First nonsampling issue
–Second nonsampling issue
etc.
in order to answer
Market
Allegheny
Altoona
Bloomington
Bucks
Canton
Charleston
Deerborn
Erie
Farmingdale
Grand Rapids
Harrisburg
Kalamazoo
Lancaster
Petersburg
Scranton
Terre Haute
Waterloo
Wheeling
Revenue Facebook Ads TV Ads
200.5
4.9
7.5
111.4
4.1
5.1
198.0
7.9
6.8
120.2
4.5
3.3
166.4
5.3
5.3
136.5
4.9
4.1
74.8
5.0
2.5
137.8
4.6
5.0
90.8
4.7
3.8
145.5
5.0
4.9
284.4
6.0
9.4
125.0
5.4
3.7
56.5
4.0
4.0
78.8
2.9
5.4
150.0
4.0
4.8
129.9
3.7
3.9
110.3
3.9
4.2
86.0
3.1
3.7
*All measures are in $100s
Viruses
3
7
7
8
12
15
22
33
40
54
65
67
68
78
85
87
99
100
120
130
133
139
140
160
Thickness
1
2
5
4
4
5
7
8
10
12
12
13
13
15
15
16
17
18
20
20
21
21
22
23
Manufacturer
X
Y
X
Y
Y
X
Y
X
X
Y
X
X
Y
Y
X
Y
X
Y
Y
X
Y
X
Y
X
Year
1
1
1
1
2
2
2
2
3
3
3
3
4
4
4
4
Quarter
1
2
3
4
1
2
3
4
1
2
3
4
1
2
3
4
Sales
3490
2940
4425
2740
2600
2400
3700
2270
2350
2075
3430
1830
2200
1745
2905
1660
Take-home
Fall 2022
1. Refer to the Excel “SAT” data posted in eLearning. (10)
a. What is the mean, median, and 30th percentile SAT score amongst all students in the
sample? (you might refer to our Descriptive Statistics Chapter Slides on calculating
the percentile). Create a histogram of the students based on “bin” widths 200 units
wide starting with 1001-1200.
b. What is the mean, median, and 30th percentile SAT score amongst Bayside students in
the sample? Create a histogram of the students based on “bin” widths 200 units wide
starting with 1001-1200.
c. What is the mean, median, and 30th percentile SAT score amongst Valley students in
the sample? Create a histogram of the students based on “bin” widths 200 units wide
starting with 1001-1200.
d. What is the probability that a randomly selected Bayside student has an SAT score <
1800? What is the probability that a randomly selected Valley student has an SAT
score < 1800? Based on your calculations, comment, if you can, on whether SAT
score is statistically independent of school.
2. Refer to the Excel “Commuting” data posted in Canvas (15)
a. What is the mean commute time for these 50 cities?
b. What is the median commute time for these 50 cities?
c. What is the variance and standard deviation of commute times for these 50 cities?
d. What is the first quartile of commute times for these 50 cities?
e. What is the 63rd percentile of commute times for these 50 cities?
f. If I randomly sample one city from this group (consider these 50 the ‘population’ if
you will) then what is the probability that the city I select will have a commute time less
than 22.25 minutes?
g. If I randomly sample two cities from this group (consider these 50 the ‘population’ if
you will) then what is the probability that both the cities I select will have a commute
time less than 22.25 minutes?
h. If I randomly sample two cities from this group (consider these 50 the ‘population’ if
you will) then what is the probability that at least one of the cities I select will have a
commute time less than 22.25 minutes?
3. Refer to the Excel “Tub Sales” data posted on eLearning which considers the sales
performance last year of a sample of the Rub-a-Dub company’s sales force: (23)
Do NOT use the “finite population” corrections for standard deviation calculation in this
problem. Just assume we’re dealing with an infinite population.
a. Provide the formal null and alternative hypotheses for a hypothesis test of the
question of whether or not the mean tub sales is really $94,000.
Assume that the underlying population of tub sales is normally distributed.
b. Conduct this hypothesis test based on the 90% confidence level (alpha = 0.10). What
is the p-value? Do you reject or fail to reject your null hypothesis from (a)? Why?
c. Create a 95% confidence interval for the mean tub sales. Explain in a sentence, in
layman’s terms, what this confidence interval implies. Would your interval suggest
rejecting or failing to reject your null hypothesis from (a) based on this interval (at the
95% level)? Why?
d. Compare your conclusions (about rejecting the null hypothesis, or not) in part “b” to
part “c”. Do these results conflict with each other? (i.e., is it OK to find these two
answers simultaneously?...if so, why?...OR, is there a conflict where it should be
impossible for these results to occur simultaneously?)
e. If I told you that the underlying population of tub sales was NOT normally
distributed, how would this change your responses to parts “b” and “c”?
f. If I told you that the underlying population of tub sales was NOT normally
distributed, BUT, your final calculations (p-value for “b”, confidence interval for “c”)
were based on double the sample size (a sample of 40 salesmen, rather than 20),
would this change your response to part “e”? If so, why? If not, why not?
You may ignore the above questions and return to the raw “Tub Sales” data.
g. The company boasts that at least 70% of its salesmen have college degrees. Provide
the formal null and alternative hypotheses for a test of this question. Is this a one or
two-tailed hypothesis?
h. Do you have a large enough sample to conduct the correct hypothesis test? Explain
with a calculation why or why not. (Hint: you need to use a specific rule taken
directly from our course slides that fits this scenario’s sampling distribution)
i. If your answer to part “h” is yes, then conduct this hypothesis test based on the 95%
confidence level. Do you reject or fail to reject your null hypothesis? Why?
4. Read the scenario described below. I am the head of internal training programs at our
organization, and I’m going to describe my professional recommendations regarding a potential
new training program that I’m considering implementing at our office… (8)
I listened to a sales pitch from a consultant regarding diversity training for my organization. I
made a deal with the consultant that my company could receive the diversity training for a
sample of management and professional employees of my company for free as long as we’d be
willing to have the results used in promotional materials (if the training is successful).
The consultant mentioned that the diversity training is particularly effective if the individuals
participating are volunteers, rather than being “forced” to attend the training program. So I
agreed to start the evaluation by taking the first 40 volunteers for the program. (Strangely, it
turned out that over half of the first 40 volunteers were either working in the Human Resources
Department of the company even though HR actually makes up about 10% of our workforce).
This training program was conducted off-site for a period of a full work week. This was done at
a very nice hotel, in order to increase the level of volunteering. When they were considering
volunteering, the potential participants were told that, after the training was concluded on
Friday afternoon, they would be permitted to have family members or significant others join
them for the weekend for a little “rest and relaxation” before returning to work on Monday,
with the company picking up the tab for the hotel. Most of the 40 volunteers involved took
advantage of this family offer.
When they came back, I was really interested in how this diversity training might impact the
volunteers, so once the trainees returned to work, I spent some time observing their interactions
with others. I think maybe the trainees noticed that I happened to be around a bit more often
than usual, but this was “unobtrusive” observation, and I was not really concerned about the
impact of my presence. After all, they should always be on their “good behavior” when they are
at work.
The consultant and I puzzled about the appropriate outcome measure for this study. Did the
training make a difference? We decided that the general tone of interactions of the volunteers
with others in the workplace was as good an outcome measure as any. But we wanted a
comparison group, so we asked each training program participant to nominate a co-worker in
the company who was as similar as possible to himself or herself with respect to demographic
factors (race, age, gender, education level, hierarchical level, and type of position). We used
these “non-volunteers” as our control group. We then tracked, for a full week, who the
volunteers were choosing to interact with and the tones of those interactions. We sent forms to
these coworkers of the volunteers and asked the coworkers to rate the general nature of their
interactions with the volunteers, including the level of positivity and professionalism in the
interaction. We also watched to see who the “control match,” non-volunteers were interacting
the most with at work, and we sent the same surveys to these coworkers of the non-volunteers.
The coworkers rated the tones of their interactions with each focal individual (either a training
“volunteer” or comparison “non-volunteer” group) with respect to how positive and how
professional that interaction was. The coworkers were asked, specifically, to comment on if
they felt like their interactions with each subject “promoted an aura of synergistic inertia in
professionalism.”
After the data were collected, I separated the surveys into two piles and calculated scores for
how positive and professional the interactions of each group were (the volunteers who were
trained and the control ‘matches’ who were not). On making the statistical comparison, I didn’t
see much difference between the “professionalism” interaction scores of the trainee volunteers
and the control non-volunteers who were not trained. But I was very gratified to discover that
the trainee group was rated much more highly on the positive tone of their interactions with
other employees than the non-volunteer, control group members. In fact, the significance level
(p-value) was 0.008, so I am sure that there is NO possibility of error in these findings. I am
ready to call the program a smashing success and advise that we make this kind of training
mandatory throughout the company. I think the consultant will probably be happy to hear of
my conclusions regarding the training too. She’ll be able to use this good news to promote her
services to other organizations.
You’re (obviously) a third-party observer to all of the above. The company president has asked
you, as the methodological expert at our company, if you have any concerns about my
conclusions and recommendations.
In Excel, create a tab and label it “4. Volunteer Scenario” (because this is question 5). In this
Excel tab, use a bullet-point format and list as many unique, non-sampling error issues as you
can. Number your list. For each issue, describe the problem that you’re identifying in a sentence
or two. In some cases, you might consider using the terminology of our “non-sampling” class
notes to describe what kind of issue you’re pointing out (not every problem here fits perfectly
into one-and-only-one category, however, so do not artificially look to put a specific label on an
item if one doesn’t apply…just describe what the problem is and WHY).
To receive full credit for this question, you’ll need to identify at least eight different nonsampling error issues. (It depends on how you “slice” the issues, because there is some overlap,
but I feel like I can spot 15 or more different serious issues here). It’s to your benefit to list as
many different issues as you possibly can, because if you only list exactly eight, and some of
them are incorrect or redundant, you’re more liable to lose points!
5. Refer to the Excel “Rust Belt” data posted on eLearning: (17)
a. Develop an estimated regression equation with the per capita Revenue serving as the
dependent variable and per capita Facebook Ads and per capita TV Ads serving as
explanatory variables. Write out this estimated equation (use the estimate values!) to
explain per capita Revenue. Do not use generic labels like ‘x1’ when you can use
problem-specific labels.
b. Show the residual plots where residuals are plotted against each explanatory variable
separately. Comment on whether you can proceed with statistical inference based on
what you see in the plots. (Hint: Don’t go looking for trouble!)
c. Provide an interpretation for the three coefficient estimates that you calculated in part
“a”. (don’t forget the intercept).
d. What would your regression model predict the revenue amount to be in a market with
0 TV Ads and 0 Facebook Ads? Is this a meaningful prediction? Answer, in a
sentence, why or why not.
e. Provide a 99% confidence interval for your estimate of the Facebook Ads Coefficient.
Interpret exactly what this 99% confidence interval means.
f. What statistic and p-value would you use to test the specific null hypothesis that:
Ho: Facebook Ads = TV Ads = 0? Do you reject or fail to reject this null hypothesis?
g. If I asked you to consider a “backward selection” approach which only included
predictors to the model that where you were confident at the 99% level, then would
your answer to part “a” change? If so, what would it change to?
h. What percentage of the variation in Revenue can be explained by the model you
developed on part “a”? How much more variation does this model explain than a
model which uses only TV Ads to help predict Revenue?
6. Refer to the Excel “Filter” data posted on eLearning: (14)
a. Estimate a regression model which explains how many viruses a filter removes from the
pump as a function of both the thickness of the filter and the filter’s manufacturer. Write out
this estimated equation to explain how many viruses are removed (use the estimate values
and the specific predictors (not ‘x1’ e.g.)!).
b. Provide the residual plots against each of the two explanatory variables you used in “a”
above (thickness and manufacturer). Comment on any irregularities that you notice. If you
notice any irregularities in part “b”, above, attempt other models which utilize quadratic
and/or interaction terms with thickness and manufacturer remaining as explanatory variables.
c. If you find a model with residuals better in line with the regression assumptions, then write
out this new, estimated model. Comment on the statistical significance levels of the
predictors and provide and comment on the new residual plots for your finalized model.
7. Refer to the Excel “Textbooks” data posted on eLearning: (13)
a. Construct a time series plot. Comment on what type of pattern exists in the data.
b. Use a regression model with quarterly dummy variables to explain sales: Qtr1 = 1 if
quarter 1, 0 otherwise, etc. etc. (HINT: If there are 4 quarters in the year…how many
dummy variables do you need in order to distinguish amongst the quarterly types of
observations?). Write out the model that you’ve estimated in equation form using the
values of your estimates. Explain, in a sentence or two, what this model tells us.
c. Use a new, simple linear regression model with “t” as the only predictor where t = 1
for the 1st quarter of year 1, t = 2 for the 2nd quarter of year 1,…, t = 16 for the 4th quarter
of year 4. Write out the model that you’ve estimated in equation form using your values
of the estimates. Explain, in a sentence or two, what this model tells us.
d. Use a new regression model with BOTH the dummy variable approach you created in
part “b” and the time predictor, “t” that you created in part “c.” Write out the model that
you’ve estimated in equation form. Explain, in a sentence or two, what this model tells
us.
e. Compute (or take from Excel) the mean squared error (MSE) from each of your
models from “b”, “c”, and “d.” (Hint: MSE is the same as MS Residual on the Excel
output). Comment, in a sentence or two, on which of the models appears the best and
why. Does this match up with the adjusted R^2 values of the models?
f. Using the model that you identified as the “best” in “e”, compute the quarterly
forecasts for next year (i.e., I should see your estimates for quarters 17-20, which would
be ‘year 5’).
Descriptive Statistics
Overview of Using Data: Definitions and Goals
(Slide 1 of 5)
• Data: The facts and figures collected, analyzed, and summarized for
presentation and interpretation.
• Variable: A characteristic or a quantity of interest that can take on
different values.
• Observation: A set of values corresponding to a set of variables.
• Variation: The difference in a variable measured over observations.
• Random variable/uncertain variable: A quantity whose values are not
known with certainty.
Overview of Using Data: Definitions and Goals
(Slide 2 of 5)
Table 2.1: Data for Dow Jones Industrial Index Companies
Company
Symbol
Industry
Share Price ($)
Volume
Apple
AAPL
Technology
195.57
21,060,685
American Express
AXP
Financial
123.16
2,387,770
Boeing
BA
Manufacturing
369.32
3,002,708
Caterpillar
CAT
Manufacturing
133.71
3,747,782
Cisco Systems
CSCO
Technology
56.08
25,533,426
Chevron
Corporation
CVX
Chemical, Oil, and
Gas
123.64
4,705,879
Disney
DIS
Entertainment
139.94
14,670,995
Overview of Using Data: Definitions and Goals
(Slide 3 of 5)
Table 2.1: Data for Dow Jones Industrial Index Companies (cont.)
Company
Symbol
Industry
Share Price ($)
Volume
Dow, Inc.
DOW
Chemical, Oil, and
Gas
49.69
4,002,257
Goldman Sachs
GS
Financial
196.06
1,828,219
The Home Depot
HD
Retail
204.74
3,583,573
IBM
IBM
Technology
138.36
2,797,803
Intel
INTC
Technology
46.85
16,658,127
Johnson & Johnson
JNJ
Pharmaceuticals
144.24
7,516,973
JPMorgan Chase
JPM
Banking
107.76
18,654,861
Coca-Cola
KO
Food and Drink
51.76
11,517,843
Overview of Using Data: Definitions and Goals
(Slide 4 of 5)
Table 2.1: Data for Dow Jones Industrial Index Companies (cont.)
Company
Symbol
Industry
Share Price ($)
Volume
McDonald’s
MCD
Food and Drink
205.71
3,017,625
3M
MMM
Conglomerate
172.03
2,730,927
Merck
MRK
Pharmaceuticals
85.24
8,909,750
Microsoft
MSFT
Technology
133.43
33,328,420
Nike
NKE
Consumer Goods
82.62
7,335,836
Pfizer
PFE
Pharmaceuticals
43.76
26,952,088
Procter & Gamble
PG
Consumer Goods
111.72
6,795,912
Travelers
TRV
Insurance
153.13
1,295,768
Overview of Using Data: Definitions and Goals
(Slide 5 of 5)
Table 2.1: Data for Dow Jones Industrial Index Companies (cont.)
Company
Symbol
Industry
Share Price ($)
Volume
UnitedHealth Group
UNH
Healthcare
247.66
3,178,942
United Technologies
UTX
Conglomerate
129.66
2,790,767
Visa
V
Financial
171.28
9,897,832
Verizon
VZ
Telecommunications
58.00
10,554,753
Walgreens Boots
Alliance
WBA
Retail
52.95
8,535,442
Wal-Mart
WMT
Retail
110.72
6.104,935
ExxonMobil
XOM
Chemical, Oil, and Gas
76.27
9,722,688
Types of Data
Population and Sample Data
Quantitative and Categorical Data
Cross-Sectional and Time Series Data
Sources of Data
Types of Data
Population and Sample Data:
• Population: All elements of interest.
• Sample: Subset of the population.
• Random sampling: A sampling method to gather a representative sample of
the population data.
Quantitative and Categorical Data:
• Quantitative data: Data on which numeric and arithmetic operations,
such as addition, subtraction, multiplication, and division, can be
performed.
• Categorical data: Data on which arithmetic operations cannot be
performed.
Types of Data
Cross-Sectional and Time Series Data:
• Cross-sectional data: Data collected from several entities at the same, or
approximately the same, point in time.
• Time series data: Data collected over several time periods.
• Graphs of time series data are frequently found in business and economic
publications.
• Graphs help analysts understand what happened in the past, identify trends
over time, and project future levels for the time series.
Types of Data
Figure 2.1: Dow Jones Industrial Average Values Since 2006
Modifying Data in Excel
Sorting and Filtering Data in Excel
Conditional Formatting of Data in Excel
Modifying Data in Excel (Slide 1 of 14)
Table 2.2: 20 Top-Selling Automobiles in United States in February 2019
Rank (by February
2019 Sales)
Model
Sales (February
2019)
Sales (February
2018)
Manufacturer
1
Toyota
Corolla
29,016
25,021
2
Toyota
Camry
24,267
30,865
3
Honda
Civic
22,979
25,816
4
Honda
Accord
20,254
19,753
5
Nissan
Sentra
17,072
17,148
6
Nissan
Altima
16,216
19,703
7
Ford
Fusion
13,163
16,721
8
Chevrolet
Malibu
10,799
11,890
Modifying Data in Excel (Slide 2 of 14)
Table 2.2: 20 Top-Selling Automobiles in United States in February 2019
(cont.)
Rank (by February
2019 Sales)
Model
Sales (February
2019)
Sales (February
2018)
Manufacturer
9
Hyundai
Elantra
10,304
15,724
10
Kia
Soul
8,592
6,631
11
Chevrolet
Cruze
7,361
12,875
12
Nissan
Versa
7,410
7,196
13
Volkswagen
Jetta
7,109
4,592
14
Kia
Optima
7,212
6,402
15
Kia
Forte
6,953
7,662
16
Hyundai
Sonata
6,481
6,700
Modifying Data in Excel (Slide 3 of 14)
Table 2.2: 20 Top-Selling Automobiles in United States in February 2019
(cont.)
Rank (by February
2019 Sales)
Model
Sales (February
2019)
Sales (February
2018)
Manufacturer
17
Tesla
Model 3
5,750
2,485
18
Dodge
Charger
6,547
7,568
19
Ford
Mustang
5,342
5,800
20
Ford
Fiesta
5,035
3,559
Modifying Data in Excel (Slide 4 of 14)
Figure 2.3: Data for 20 TopSelling Automobiles
Entered into Excel with
Percent Change in Sales
from 2018
Modifying Data in Excel (Slide 5 of 14)
Sorting and Filtering Data in Excel:
• To sort the automobiles by February 2019 sales:
• Step 1: Select cells A1:F21.
• Step 2: Click the Data tab in the Ribbon.
• Step 3: Click Sort in the Sort & Filter group.
• Step 4: Select the check box for My data has headers.
• Step 5: In the first Sort by dropdown menu, select Sales (February 2018).
• Step 6: In the Order dropdown menu, select Largest to Smallest.
• Step 7: Click OK.
Modifying Data in Excel (Slide 6 of 14)
Figure 2.4: Using Excel’s
Sort Function to Sort
the Top-Selling
Automobiles Data
Modifying Data in Excel (Slide 7 of 14)
Figure 2.5: TopSelling Automobiles
Data Sorted by Sales
in February 2018
Sales
Modifying Data in Excel (Slide 8 of 14)
Sorting and Filtering Data in Excel (cont.):
• Using Excel’s Filter function to see the sales of models made by Nissan:
• Step 1: Select cells A1:F21.
• Step 2: Click the Data tab in the Ribbon.
• Step 3: Click Filter in the Sort & Filter group.
• Step 4: Click on the Filter Arrow in column B, next to Manufacturer.
• Step 5: If all choices are checked, you can easily deselect all choices by
unchecking (Select All). Then select only the check box for Nissan.
• Step 6. Click OK.
Modifying Data in Excel (Slide 9 of 14)
Figure 2.6: Top-Selling Automobiles Data Filtered to Show Only
Automobiles Manufactured by Nissan
Modifying Data in Excel (Slide 10 of 14)
Conditional Formatting of Data in Excel:
• Makes it easy to identify data that satisfy certain conditions in a data set.
• To identify the automobile models in Table 2.2 for which sales had
decreased from February 2018 to February 2019:
• Step 1: Starting with the original data shown in Figure 2.3, select cells
F1:F21.
• Step 2: Click on the Home tab in the Ribbon.
• Step 3: Click Conditional Formatting in the Styles group.
• Step 4: Select Highlight Cells Rules, and click Less Than… from the
dropdown menu.
• Step 5: Enter 0% in the Format cells that are LESS THAN: box.
• Step 6: Click OK.
Modifying Data in Excel (Slide 11 of 14)
Figure 2.7: Using
Conditional Formatting
in Excel to Highlight
Automobiles with
Declining Sales from
February 2018
Modifying Data in Excel (Slide 12 of 14)
Figure 2.8: Using
Conditional Formatting
in Excel to Generate
Data Bars for the TopSelling Automobiles
Data
Modifying Data in Excel (Slide 13 of 14)
Conditional Formatting of Data in Excel (cont.):
• Quick Analysis button appears just outside the bottom-right corner of a
group of selected cells.
• It provides shortcuts for Conditional Formatting, adding Data Bars, and
other operations.
Modifying Data in Excel (Slide 14 of 14)
Figure 2.9 Excel Quick Analysis Button Formatting Options
Creating Distributions from Data
Frequency Distributions for Categorical Data
Relative Frequency and Percent Frequency Distributions
Frequency Distributions for Quantitative Data
Histograms
Cumulative Distributions
Creating Distributions from Data (Slide 1 of 18)
Frequency Distributions for Categorical Data:
• Frequency distribution: A summary of data that shows the number
(frequency) of observations in each of several nonoverlapping classes,
typically referred to as bins.
Creating Distributions from Data (Slide 2 of 18)
Table 2.3: Data from a Sample of 50 Soft Drink Purchases
Coca-Cola
Diet Coke
Pepsi
Diet Coke
Coca-Cola
Coca-Cola
Dr. Pepper
Diet Coke
Pepsi
Pepsi
Coca-Cola
Dr. Pepper
Sprite
Coca-Cola
Diet Coke
Coca-Cola
Coca-Cola
Sprite
Coca-Cola
Diet Coke
Coca-Cola
Diet Coke
Coca-Cola
Sprite
Pepsi
Coca-Cola
Coca-Cola
Coca-Cola
Pepsi
Coca-Cola
Sprite
Dr. Pepper
Pepsi
Diet Coke
Pepsi
Coca-Cola
Coca-Cola
Coca-Cola
Pepsi
Dr. Pepper
Coca-Cola
Diet Coke
Pepsi
Pepsi
Pepsi
Pepsi
Coca-Cola
Dr. Pepper
Pepsi
Sprite
Creating Distributions from Data (Slide 3 of 18)
Table 2.4: Frequency Distribution of Soft Drink Purchases
Soft Drink
Frequency
Coca-Cola
19
Diet Coke
8
Dr. Pepper
5
Pepsi
13
Sprite
5
Total
50
• The frequency distribution summarizes information about
the popularity of the five soft drinks:
• Coca-Cola is the leader.
• Pepsi is second.
• Diet Coke is third.
• Sprite and Dr. Pepper are tied for fourth.
Creating Distributions from Data (Slide 4 of 18)
Figure 2.10: Creating a Frequency
Distribution for Soft Drinks Data in Excel
Creating Distributions from Data (Slide 5 of 18)
Relative Frequency and Percent Frequency Distributions:
• Relative frequency distribution: A tabular summary of data showing the
relative frequency for each bin.
• Percent frequency distribution: Summarizes the percent frequency of
the data for each bin.
• Used to provide estimates of the relative likelihoods of different values of a
random variable.
Creating Distributions from Data (Slide 6 of 18)
Table 2.5: Relative Frequency and Percent Frequency Distributions of
Soft Drink Purchases
Soft Drink
Coca-Cola
Relative
Frequency
0.38
Percent
Frequency (%)
38
Diet Coke
0.16
16
Dr. Pepper
0.10
10
Pepsi
0.26
26
Sprite
0.10
10
Total
1.00
100
Creating Distributions from Data (Slide 7 of 18)
Frequency Distributions for Quantitative Data:
• Three steps necessary to define the classes for a frequency distribution
with quantitative data:
1. Determine the number of nonoverlapping bins.
2. Determine the width of each bin.
3. Determine the bin limits.
Creating Distributions from Data (Slide 8 of 18)
Table 2.6: Year-End Audit Times (Days)
12
15
20
22
14
14
15
27
21
18
19
18
22
33
16
18
17
23
28
13
Creating Distributions from Data (Slide 9 of 18)
Table 2.7: Frequency, Relative Frequency, and Percent Frequency
Distributions for the Audit Time Data
Audit Times
(days)
10–14
Frequency
4
Relative
Frequency
0.20
Percent
Frequency
20
15–19
8
0.40
40
20–24
5
0.25
25
25–29
2
0.10
10
30–34
1
0.05
5
Creating Distributions from Data (Slide 10 of 18)
Figure 2.11: Using Excel
to Generate a
Frequency Distribution
for Audit Times Data
Creating Distributions from Data (Slide 11 of 18)
Histograms:
• Histogram: A common graphical presentation of quantitative data.
• Constructed by placing the variable of interest on the horizontal axis and
the selected frequency measure (absolute frequency, relative frequency,
or percent frequency) on the vertical axis.
• The frequency measure of each class is shown by drawing a rectangle
whose base is the class limits on the horizontal axis and whose height is
the corresponding frequency measure.
Creating Distributions from Data (Slide 12 of 18)
Figure 2.12: Histogram for the Audit Time Data
Creating Distributions from Data (Slide 13 of 18)
Figure 2.13: Creating a
Histogram for the Audit Time
Data Using Data Analysis
Toolpak in Excel
Creating Distributions from Data (Slide 14 of 18)
Figure 2.14: Completed Histogram for the Audit Time Data Using Data
Analysis ToolPak in Excel
Creating Distributions from Data (Slide 15 of 18)
Histograms (cont.):
• Histograms provide information about the shape, or form, of a
distribution.
• Skewness: Lack of symmetry.
• Skewness is an important characteristic of the shape of a
distribution.
Creating Distributions from Data (Slide 16 of 18)
Figure 2.15: Histograms
Showing Distributions with
Different Levels of Skewness
Creating Distributions from Data (Slide 17 of 18)
Cumulative Distributions
• Cumulative frequency distribution: A variation of the frequency
distribution that provides another tabular summary of quantitative data.
• Uses the number of classes, class widths, and class limits developed for the
frequency distribution.
• Shows the number of data items with values less than or equal to the upper
class limit of each class.
Creating Distributions from Data (Slide 18 of 18)
Table 2.8: Cumulative Frequency, Cumulative Relative Frequency, and
Cumulative Percent Frequency Distributions for the Audit Time Data
Audit Time (days)
Less than or equal to 14
Cumulative
Frequency
4
Cumulative
Relative
Frequency
0.20
Cumulative
Percent
Frequency
20
Less than or equal to 19
12
0.60
60
Less than or equal to 24
17
0.85
85
Less than or equal to 29
19
0.95
95
Less than or equal to 34
20
1.00
100
Measures of Location
Mean (Arithmetic Mean)
Median
Mode
Geometric Mean
Measures of Location (Slide 1 of 13)
Mean/Arithmetic Mean
Average value for a variable.
The mean is denoted by x .
n = sample size.
x1 = variable of x for the first observation.
x2 = variable of x for the second observation.
xi = variable of x for the ith observation.
Measures of Location (Slide 2 of 13)
Table 2.9: Data on Home Sales
in a Cincinnati, Ohio, Suburb
Home Sale
Selling Price ($)
1
138,000
2
254,000
3
186,000
4
257,500
5
108,000
6
254,000
7
138,000
8
298,000
9
199,500
10
208,000
11
142,000
12
456,250
Measures of Location (Slide 3 of 13)
Computation of Sample Mean
• Illustration: Computation of the mean home selling price for the
sample of 12 home sales.
xi x1 + x2 + + x12
x=
=
n
12
138,000 + 254,000 + 456,250
=
12
2,639,250
=
= 219,937.50
12
Measures of Location (Slide 4 of 13)
Median
• Median: Value in the middle when the data are arranged in
ascending order.
• Middle value, for an odd number of observations.
• Average of two middle values, for an even number of observations.
Measures of Location (Slide 5 of 13)
Computation of Sample Median
• Illustration: When the number of observations are odd:
• Consider the class size data for a sample of five college classes:
46 54 42 46 32
• Arrange the class size data in ascending order:
32 42 46 46 54
• Middlemost value in the data set = 46.
• Median is 46.
Measures of Location (Slide 6 of 13)
Computation of Sample Median
• Illustration: When the number of observations are even:
• Consider the data on home sales in Cincinnati, Ohio, Suburb (Table 2.9).
• Arrange the data in ascending order:
108,000 138,000 138,000 142,000 186,000 199,500 208,000
254,000 254,000 257,500 298,000 456,250
• Median = average of two middle values:
199,500 + 208,000
Median =
= 203,750
2
Measures of Location (Slide 7 of 13)
Mode:
• Mode: Value that occurs most frequently in a data set.
• Consider the class size data:
32 42 46 46 54
• Observe: 46 is the only value that occurs more than once.
• Mode is 46.
• Multimodal data: Data contain at least two modes.
• Bimodal data: Data contain exactly two modes.
Measures of Location (Slide 8 of 13)
Figure 2.16: Calculating
the Mean, Median, and
Modes for the Home
Sales Data using Excel
Measures of Location (Slide 9 of 13)
Geometric Mean:
• Geometric mean: A measure of location that is calculated by finding the
nth root of the product of n values
• Used in analyzing growth rates in financial data.
• Sample geometric mean:
Measures of Location (Slide 10 of 13)
Table 2.10: Percentage Annual Returns and Growth Factors for the
Mutual Fund Data:
• Illustration: Consider the percentage annual returns and growth factors
for the mutual fund data over the past 10 years.
• We will determine the mean rate of growth for the fund over the 10-year
period.
Measures of Location (Slide 11 of 13)
Table 2.10: Percentage
Annual Returns and Growth
Factors for the Mutual Fund
Data (cont.)
Year
Return (%)
Growth Factor
1
−22.1
0.779
2
28.7
1.287
3
10.9
1.109
4
4.9
1.049
5
15.8
1.158
6
5.5
1.055
7
−37.0
0.630
8
26.5
1.265
9
15.1
1.151
10
2.1
1.021
Measures of Location (Slide 12 of 13)
Computation of Geometric Mean:
• Solution:
• Product of the growth factors:
$100 (0.779)(1.287)(1.109) (1.049 ) (1.158)(1.055)(0.630)(1.265)(1.151)(1.021)
= $100 (1.335) = $133.45
• Geometric mean of the growth factors:
xg = 10 1.335 = 1.029.
• Conclude that annual returns grew at an average annual rate of
(1.029 − 1)100% or 2.9%.
Measures of Location (Slide 13 of 13)
Figure 2.17: Calculating
the Geometric Mean for
the Mutual Fund Data
Using Excel
Measures of Variability
Range
Variance
Standard Deviation
Coefficient of Variation
Measures of Variability (Slide 1 of 10)
Table 2.11: Annual
Payouts for Two
Different Investment
Funds
Year
Fund A ($)
Fund B ($)
1
1,100
700
2
1,100
2,500
3
1,100
1,200
4
1,100
1,550
5
1,100
1,300
6
1,100
800
7
1,100
300
8
1,100
1,600
9
1,100
1,500
10
1,100
350
11
1,100
460
Measures of Variability (Slide 2 of 10)
Table 2.11: Annual
Payouts for Two Different
Investment Funds (cont.)
Year
Fund A ($)
Fund B ($)
12
1,100
890
13
1,100
1,050
14
1,100
800
15
1,100
1,150
16
1,100
1,200
17
1,100
1,800
18
1,100
100
19
1,100
1,750
20
1,100
1,000
Mean
1,100
1,100
Measures of Variability (Slide 3 of 10)
Figure 2.18: Histograms for Payouts of Past 20 Years from Fund A and
Fund B
Measures of Variability (Slide 4 of 10)
Computation of Range
Range:
• The range can be found by subtracting the smallest value from the largest value
in a data set.
• Illustration: Consider the data on home sales in a Cincinnati, Ohio, suburb.
• Largest home sales price: $456,250.
• Smallest home sales price: $108,000.
Range = Largest value − Smallest value
= $456,250 − $108,000
= $348,250
• Drawback: Range is based on only two of the observations and thus is highly
influenced by extreme values.
Measures of Variability (Slide 5 of 10)
Variance
• Variance is a measure of variability that utilizes all the data.
• It is based on the deviation about the mean, which is the difference
between the value of each observation ( xi ) and the mean.
• The deviations about the mean are squared while computing the
variance.
( xi − )
• Population variance: =
.
N
2
2
Measures of Variability (Slide 6 of 10)
Table 2.12: Computation of Deviations and Squared Deviations About the Mean for
the Class Size Data
( xi − x ) 256
• Computation of Sample Variance: s =
=
= 64.
n −1
4
2
2
Measures of Variability (Slide 7 of 10)
Standard Deviation:
• Standard deviation is the positive square root of the variance.
• Measured in the same units as the original data.
• For population, = 2 .
Measures of Variability (Slide 8 of 10)
Figure 2.19:
Calculating Variability
Measures for the
Home Sales Data in
Excel
Measures of Variability (Slide 9 of 10)
Coefficient of Variation:
• The coefficient of variation is a descriptive statistic that indicates how
large the standard deviation is relative to the mean.
• Expressed as a percentage.
Measures of Variability (Slide 10 of 10)
Computation of Coefficient of Variation:
Illustration:
• Consider the class size data:
46 54 42 46 32
• Mean, x = 44.
• Standard deviation, s = 8.
• Coefficient of variation =
8
100
% = 18.2%.
44
Analyzing Distributions
Percentiles
Quartiles
z-Scores
Empirical Rule
Identifying Outliers
Boxplots
Analyzing Distributions (Slide 1)
Percentiles:
• A percentile is the value of a variable at which a specified (approximate)
percentage of observations are below that value.
• The pth percentile tells us the point in the data where:
• Approximately p percent of the observations have values less than the pth
percentile.
• Approximately (100 − p ) percent of the observations have values greater than
the pth percentile.
Analyzing Distributions (Slide 2)
Illustration:
• To determine the 85th percentile for the home sales data in Table 2.9:
1. Arrange the data in ascending order:
108,000 138,000 138,000 142,000 186,000 199,500
208,000 254,000 254,000 257,500 298,000 456,250
p
85
2. Compute L85 =
( n + 1) = (12 + 1) = 11.05.
100
100
3. The interpretation of L85 = 11.05 is that the 85th percentile is 5% of the way
between the value in position 11 and value in position 12.
Analyzing Distributions (Slide 3)
Illustration (cont.):
• To determine the 85th percentile for the home sales data in Table 2.9.
• The value in the 11th position is 298,000.
• The value in the 12th position is 456,250.
• $305,912.50 represents the 85th percentile of the home sales data:
85th percentile = 298,000 + 0.05 ( 456,250 − 298,000 )
= 298,000 + 0.05 (158,250 )
= 305,912.50
Analyzing Distributions (Slide 4)
Quartiles:
• Quartiles: When the data is divided into four equal parts:
• Each part contains approximately 25% of the observations.
• Division points are referred to as quartiles.
Q1 = first quartile, or 25th percentile.
Q2 = second quartile, or 50th percentile (also the median).
Q3 = third quartile or 75th percentile.
• The difference between the third and first quartiles is often referred to as
the interquartile range, or IQR.
Analyzing Distributions (Slide 5)
z-Scores:
• The z-score measures the relative location of a value in the data set.
• Helps to determine how far a particular value is from the mean relative
to the data set’s standard deviation.
• Often called the standardized value.
Analyzing Distributions (Slide 6)
• z-Scores (cont.):
If x1 , x2 ,
, xn is a sample of n observations:
Analyzing Distributions (Slide 7)
Table 2.13: z-Scores for the Class Size Data
For class size data, x = 44 and s = 8.
For observations with a value mean, z -score 0.
For observations with a value mean, z -score 0.
Analyzing Distributions (Slide 8)
Figure 2.20: Calculating z-Scores for the Home Sales Data in Excel
Analyzing Distributions (Slide 9)
Empirical Rule:
• When the distribution of data exhibits a symmetric bell-shaped
distribution (as shown in Figure 2.21), the empirical rule can be used to
determine the percentage of data values that are within a specified
number of standard deviations of the mean.
• For data having a bell-shaped distribution:
• Approximately 68% of the data values will be within 1 standard deviation.
• Approximately 95% of the data values will be within 2 standard deviations.
• Almost all the data values will be within 3 standard deviations.
Analyzing Distributions (Slide 10)
Figure 2.21: A Symmetric
Bell-Shaped Distribution
Analyzing Distributions (Slide 11)
Identifying Outliers:
• Outliers: Extreme values in a data set.
• They can be identified using standardized values (z-scores).
• Any data value with a z-score less than –3 or greater than +3 is an outlier.
• Such data values can then be reviewed to determine their accuracy and
whether they belong in the data set.
Analyzing Distributions (Slide 12)
Boxplots:
• A boxplot is a graphical summary of the distribution of data.
• Developed from the quartiles for a data set.
Figure 2.22: Boxplot for the
Home Sales Data
Analyzing Distributions (Slide 13)
Figure 2.23: Boxplots Comparing Home Sale Prices in Different
Communities
Measures of Association Between
Two Variables
Scatter Charts
Covariance
Correlation Coefficient
Measures of Association Between Two
Bottled Water Sales
Variables (Slide 1 of 11)
High Temperature (°F)
(cases)
Table 2.14: Data for Bottled
Water Sales at Queensland
Amusement Park for a
Sample of 14 Summer Days
78
79
80
80
82
83
85
86
87
87
88
88
90
92
23
22
24
22
24
26
27
25
28
26
29
30
31
31
Measures of Association Between Two
Variables (Slide 2 of 11)
Scatter Charts:
• A scatter chart is a useful graph for analyzing the relationship between
two variables.
• The scatter chart in Figure 2.26 is an example of a positive relationship,
because when one variable (high temperature) increases, the other
variable (sales of bottled water) generally also increases.
• The scatter chart also suggests that a straight line could be used as an
approximation for the relationship between high temperature and sales
of bottled water.
Measures of Association Between Two
Variables (Slide 3 of 11)
Figure 2.26: Chart Showing
the Positive Linear Relation
Between Sales and High
Temperatures
Measures of Association Between Two
Variables (Slide 4 of 11)
Covariance:
• Covariance is a descriptive measure of the linear association between
two variables:
Popular covariance, xy =
( xi − x ) ( yi − y )
N
.
Measures of Association Between Two
Variables (Slide 5 of 11)
Table 2.15: Sample Covariance
Calculations for Daily High
Temperature and Bottled Water
Sales at Queensland Amusement
Park
Measures of Association Between Two
Variables (Slide 6 of 11)
Figure 2.27: Calculating
Covariance and Correlation
Coefficient for Bottled Water
Sales Using Excel
Measures of Association Between Two
Variables (Slide 7 of 11)
Figure 2.28: Scatter Diagrams and Associated Covariance Values for Different
Variable Relationships
sxy Positive
(x and y are positively
linearly related)
sxy Approximately 0:
(x and y are not
linearly related)
sxy Negative:
(x and y are negatively
linearly related)
Measures of Association Between Two
Variables (Slide 8 of 11)
Correlation Coefficient:
• The correlation coefficient measures the relationship between two variables.
• Not affected by the units of measurement for x and y.
Measures of Association Between Two Variables
(Slide 9 of 11)
Interpretation of Correlation Coefficient:
−1 r +1
r value
0
Relationship between
the x and y variables
Negative linear
No linear relationship
Positive linear
Measures of Association Between Two
Variables (Slide 10 of 11)
Computation of Correlation Coefficient:
Illustration:
• To determine the sample correlation coefficient for bottled water sales at
Queensland Amusement Park:
sxy
12.8
rxy =
=
= 0.93
sx sy ( 4.36 )( 3.15)
• There is a very strong linear relationship between high temperature and
sales.
Measures of Association Between Two
Variables (Slide 11 of 11)
Figure 2.29: Example
of Nonlinear
Relationship Producing
a Correlation
Coefficient Near Zero
Practice problems, on eLearning!
• Some end-of-chapter exercises are posted in this week’s tab. I’ve
posted a copy of the problems so that you will definitely have the
“correct” version.
• Excel data is provided for problems, when specified in the problem.
• I’ve provided the solutions manual to the book by which you may
check your answers. I encourage you not to “peek” at the solutions
until you try a problem yourself.
• You must judge how much practice you want to undertake in order to
feel comfortable with you mastery of the material. This is a graduatelevel course, and you are responsible for being self-aware of your
mastery level!
Probability: An Introduction
to Modeling Uncertainty
2
Introduction
• Probability is the numerical measure of the likelihood that an event will
occur. It is measured in decimal form, with…
• 0 meaning no possibility of the event occurring
• 0.50 meaning the possibility of the event occurring, or not, are equal
• 1 meaning absolute certainty of the event occurring
• Often, we instead refer to these in percent terms… 0%, 50%, 100%, but be careful in
doing so if you’re using probability as part of a calculation, formula, rule, etc.
• This measure of uncertainty is often communicated through a probability
distribution
• Extremely helpful in providing additional information about an event
• Can be used to help a decision maker evaluate possible actions and
determine best course of action
Events and Probabilities
Events and Probabilities (Slide 1 of 6)
• A random experiment is a process that generates well-defined
outcomes….this means the outcome is ‘up in the air’
• By specifying all possible outcomes, we identify the sample space for
a random experiment; examples:
• A coin toss. (H or T)
• Rolling a die. (1, 2, 3, 4, 5, 6)
Events and Probabilities (Slide 2 of 6)
Random Experiments and Experimental Outcomes
Random Experiment
Experimental Outcomes
Toss a coin
Head, tail
Roll a die
1, 2, 3, 4, 5, 6
Conduct a sales call
Purchase, no purchase
Hold a particular share of stock for one year
Price of stock goes up, price of stock goes down,
no change in stock price
Reduce price of product
Demand goes up, demand goes down, no change
in demand
Events and Probabilities (Slide 3 of 6)
• Example: California Power & Light Company (CP&L).
• CP&L is starting a project designed to increase the generating capacity
of one of its plants in southern California.
• Analysis of similar construction projects indicates that the possible
completion times (rounded, in months) for the project are 8, 9, 10,
11, and 12 months.
Events and Probabilities (Slide 4 of 6)
Completion Times for 40 CP&L Projects
Events and Probabilities (Slide 5 of 6)
• The probability of an event is equal to the sum of probabilities of
outcomes for the event.
• CP&L example: Let C denote the event that the project is completed
in 10 months or less, C = {8,9,10}.
• The probability of event C, denoted P ( C ) , is given by
P(C ) = P(8) + P(9) + P(10) = 0.15 + 0.25 + 0.30 = 0.70
• We can tell CP&L management that there is a 0.70 probability that the
project will be completed in 10 months or less.
Some Basic Relationships of
Probability
Complement of an Event
Addition Law
Some Basic Relationships of Probability
(Slide 1 of 11)
Complement of an Event:
• Given an event A, the complement of A is defined to be the event consisting of
all outcomes that are not in A.
• Figure below shows what is known as a Venn diagram, which illustrates the
concept of a complement:
• Rectangular area represents the sample space for the random experiment and
contains all possible outcomes.
• Circle represents event A and contains only the outcomes that belong to A.
• Shaded region of the rectangle contains all outcomes not in event A.
• Of course, when A and A-complement are taken, as a whole, they describe ALL
possible outcomes that could occur for event A
Some Basic Relationships of Probability
(Slide 2 of 11)
Venn Diagram for Event A
Some Basic Relationships of Probability
(Slide 3 of 11)
In any probability application, either event A or its complement AC
must occur.
Solving for P( A), we obtain the following result:
The probability of an event A can be computed easily if the probability of
its complement is known.
Some Basic Relationships of Probability
(Slide 4 of 11)
Addition Law:
• The addition law is helpful when we are interested in knowing the
probability that at least one of two events will occur.
• Concepts related to the combination of events:
• The union of events.
• The intersection of events.
Some Basic Relationships of Probability
(Slide 5 of 11)
• Given two events A and B, the union of A and B is defined as the
event containing all outcomes belonging to A or B or both.
• The union of A and B is denoted by A B.
• The Venn diagram below depicts the union of A and B:
• One circle contains all the outcomes of A.
• The other circle contains all the outcomes of B.
Some Basic Relationships of Probability
(Slide 6 of 11)
Figure 4.2: Venn Diagram for the Union of Events A and B
Some Basic Relationships of Probability
(Slide 7 of 11)
• The definition of the intersection of A and B is the event containing
the outcomes that belong to both A and B.
• The intersection of A and B is denoted by A B.
• The Venn diagram depicting the intersection of A and B is shown in
the next figure:
• The area in which the two circles overlap is the intersection.
• It contains outcomes that are in both A and B.
Some Basic Relationships of Probability
(Slide 8 of 11)
Venn Diagram for the Intersection of Events A and B
Some Basic Relationships of Probability
(Slide 9 of 11)
• The addition law provides a way to compute the probability that event A or event
B or both will occur.
• Used to compute the probability of the union of two events.
• A special case arises for mutually exclusive events:
• If the occurrence of one event precludes the occurrence of the other.
• If the events have no outcomes in common.
Some Basic Relationships of Probability
(Slide 10 of 11)
Figure 4.4: Venn Diagram for Mutually Exclusive Events
Some Basic Relationships of Probability
(Slide 11 of 11)
Conditional Probability
Independent Events
Multiplication Law
Bayes’ Theorem
Conditional Probability Example
• Conditional probability: When the probability of one event is
dependent on whether some related event has already occurred.
• Illustration: Lancaster Savings and Loan:
• Interested in mortgage default risk.
• Interested in whether the probability of a customer defaulting differs by
marital status.
Conditional Probability
Subset of Data from 300 Home Mortgages of Customers at Lancaster
Savings and Loan…a few observations…
Customer
No.
Age
1
37
2
Marital
Status
Annual
Income
Mortgage
Amount
Payments
per Year
Total Amount
Paid
Default on
Mortgage?
Single
$172,125.70
$473,402.96
24
$581,885.13
Yes
31
Single
$108,571.04
$300,468.60
12
$489,320.38
No
3
37
Married
$124,136.41
$330,664.24
24
$493,541.93
Yes
4
24
Married
$79,614.04
$230,222.94
24
$449,682.09
Yes
5
27
Single
$68,087.33
$282,203.53
12
$520,581.82
No
6
30
Married
$59,959.80
$251,242.70
24
$356,711.58
Yes
Conditional Probability
Crosstabulation of Marital Status and if Customer Defaults on Mortgage
Marital Status
No Default
Default
Total
Married
64
79
143
Single
116
41
157
Total
180
120
300
The probability that a customer defaults on his or her mortgage is
120 300 = 0.4.
The probability that a customer does not default on his or her mortgage is
1 − 0.4 = 0.6 or 180 300.
Conditional Probability
PivotTable for Marital Status
and Whether Customer
Defaults on Mortgage
Conditional Probability Example Cont’d
• When values give the probability of the intersection of two events, the
probabilities are called joint probabilities.
• Marginal probabilities are found by summing the joint probabilities in the
corresponding row or column of the joint probability table.
• Conditional probabilities can be computed as the ratio of joint probability to a
marginal probability.
Conditional Probability
Joint Probability Table for Customer Mortgage Prepayments
Conditional Probability
Using Excel PivotTable to
Calculate Conditional
Probabilities
Check out the Conditional Probabilities on Default
from the Calculations in Excel…
• P(Default|Married) = 0.552
• P(Default|Single) = 0.261
Are default likelihood and marital status independent?
NO! If I KNOW about your marital status, that changes my
opinion about your likelihood of default
THIS IS NOT PERSONAL!!!! It is a matter of data
Conditional Probability
Independent Events:
• If the probability of event D is not changed by the existence of event M,
then we would say that events D and M are independent events.
• Otherwise, the events are dependent.
Conditional Probability
Multiplication Law:
• Multiplication law can be used to calculate the probability of the
intersection of two events.
• Based on the definition of conditional probability.
Conditional Probability
• Special case in which events A and B are independent.
• To compute the probability of the intersection of two independent
events, simply multiply the probabilities of each event.
Conditional Probability
Bayes’ Theorem:
• Often begin the analysis with initial or prior probability estimates for
specific events of interest.
• Then, obtain additional information about events.
• Given new information, update the prior probability values by
calculating revised probabilities, referred to as posterior
probabilities.
• Bayes’ theorem provides a means for making these probability
calculations.
Conditional Probability
• Example: A manufacturing firm receives shipments of parts from two
different suppliers:
• 65% of the parts purchased from supplier 1.
• 35% of the parts purchased from supplier 2.
• Quality of purchased parts varies according to their source.
Conditional Probability
Historical Quality Levels for Two Suppliers
• Historical data suggest the quality ratings of the two suppliers:
% Good Parts
% Bad Parts
Supplier 1
98
2
Supplier 2
95
5
• The figure shows a diagram that depicts the process of the firm receiving a
part from one of the suppliers and then discovering that the part is good or
bad as a two-step random experiment.
Conditional Probability
Diagram for Two-Supplier
Example
Step 1 shows that the part
comes from one of two
suppliers and Step 2 shows
whether the part is good or
bad.
Conditional Probability
• The process of computing joint probabilities can be depicted in what
is called a probability tree.
• From left to right through the tree:
• The probabilities for each branch at step 1 are prior probabilities.
• The probabilities for each branch at step 2 are conditional probabilities.
• To find the probability of each experimental outcome, multiply the
probabilities on the branches leading to the outcome.
Conditional Probability
Probability Tree for Two-Supplier Example
Conditional Probability
• Suppose the parts from the two suppliers are used in the firm’s
manufacturing process and a machine breaks while attempting the process
using a bad part
• Given the information that the part is bad, what is the probability that it came
from supplier 1 and what is the probability that it came from supplier 2?
• With the information in the probability tree, Bayes’ theorem can be used to
answer these questions… 0.013 / (0.013+ 0.0175) = 0.426 P(Supplier of 1)
Conditional Probability
• Bayes’ theorem is applicable when events for which we want to
compute posterior probabilities are mutually exclusive and their
union is the entire sample space.
Random Variables
Discrete Random Variables
Continuous Random Variables
Random Variables
• In probability terms, a random variable is a numerical description of
the outcome of a random experiment.
• Random variables are quantities whose values are not known with
certainty.
• A random variable can be classified as being either:
• Discrete.
• Continuous.
Random Variables
Discrete Random Variables:
• A random variable that can take on only specified discrete values is
referred to as a discrete random variable.
• Our first table provides examples of discrete random variables.
• The next table repeats the joint probability table for the Lancaster
Savings and Loan data, but with the values labeled as random
variables.
Random Variables
Examples of Discrete Random Variables
Random Experiment
Random Variable (x)
Possible Values for the
Random Variable
Flip a coin
Face of a coin showing
1 if heads; 0 if tails
Roll a die
Number of dots showing on
top of die
1, 2, 3, 4, 5, 6
Contact five customers
Number of customers who
place an order
0, 1, 2, 3, 4, 5
Operate a health care clinic
for one day
Number of patients who
arrive
0, 1, 2, 3, …
Offer a customer the choice
of two products
Product chosen by customer
0 if none; 1 if choose product
A; 2 if choose product B
Random Variables
Joint Probability Table for Customer Mortgage Prepayments
Random Variables
Continuous Random Variables:
• A random variable that may assume any numerical value in an
interval or collection of intervals is called a continuous random
variable.
• Technically, relatively few random variables are truly continuous;
examples are values related to time, weight, distance, and
temperature.
• Many discrete random variables have a large number of potential
outcomes and so can be effectively modeled as continuous random
variables.
Random Variables
Examples of Continuous Random Variables
Discrete Probability Distributions
Custom Discrete Probability Distribution
Expected Value and Variance
Discrete Uniform Probability Distribution
Binomial Probability Distribution
Poisson Probability Distribution
Discrete Probability Distributions
• The probability distribution for a random variable describes the
range and relative likelihood of possible values for a random variable.
• For a discrete random variable x, the probability distribution is
defined by the probability mass function, denoted byf (x).
• The probability mass function provides the probability for each value
of the random variable.
• We can present probability distributions graphically.
Discrete Probability Distributions
Custom Discrete Probability Distribution:
• A probability that is generated from observations is called an
empirical probability distribution.
• An empirical probability is considered a custom discrete probability
distribution if it is discrete and the possible values of the random
variable have different values:
• Useful for describing different possible scenarios that have different
probabilities.
• Probabilities generated using either the subjective method or the
relative frequency method.
Discrete Probability Distributions (Example)
Summary Table of Number of Payments Made per Year
• Example: The random variable describing the number of mortgage
payments made per year by randomly chosen customers.
Discrete Probability Distributions
Excel PivotTable for
Number of Payments
Made per Year
Discrete Probability Distributions
Expected Value and Variance:
• The expected value, or mean, of a random variable is a measure of
the central location for the random variable.
Discrete Probability Distributions
Calculation of the Expected Value for Number of Payments Made per
Year by a Lancaster Savings and Loan Mortgage Customer
If Lancaster Savings and Loan signs a new mortgage customer, the
expected number of payments per year for this customer is 13.8.
Discrete Probability Distributions
Using Excel SUMPRODUCT
Function to Calculate the
Expected Value for Number
of Payments Made per Year
by a Lancaster Savings and
Loan Mortgage Customer
Discrete Probability Distributions
• Variance is a measure of variability in the values of a random variable:
An essential part of the variance formula is the deviation, x − ,
which measures how far a particular value of the random variable is from
the expected value, or mean, .
Discrete Probability Distributions
Calculation of the Variance for Number of Payments Made per Year by
a Lancaster Savings and Loan Mortgage Customer
The standard deviation, , is defined as the positive square root of the
variance.
The standard deviation for the payments made per year by a mortgage
customer is 42.360 = 6.508.
Discrete Probability Distributions
Excel Calculation of the Variance for Number of Payments Made per
Year by a Lancaster Savings and Loan Mortgage Customer
Discrete Probability Distributions (Besides the
custom one!)
Discrete Uniform Probability Distribution (Check out Excel Distribution
example)
• When the possible values of the probability mass function are all equal,
then the probability distribution is a discrete uniform probability
distribution
• Where n = the number of unique values that may be assumed by the
random variable
• Expected value, E(n) = (a+b)/2 where a is the smallest value and b is the largest value
• Standard deviation, s(n) = Sqrt[{(b-a+1)2 -1}/12]
Discrete Probability Distributions
Binomial Probability Distribution:
• A binomial probability distribution is a discrete probability
distribution that can be used to describe many situations in which a
fixed number (n) of repeated identical and independent trials has
two, and only two, possible outcomes:
• Success.
• Failure.
Discrete Probability Distributions
The probability mass function for a binomial random variable that
calculates the probability of x successes in n independent events.
Discrete Probability Distributions
Probability Distribution for the Number of Customers Who Click on the
Link in the Martin’s Targeted E-Mail
• Example: Martin’s, an online specialty clothing store, sends out targeted e-mails
to its best customers notifying them about special discounts available only to the
recipients.
Discrete Probability Distributions
Graphical
Representation of the
Probability Distribution
for the Number of
Customers Who Click
on the Link in the
Martin’s Targeted EMail
Discrete Probability Distributions
Excel Worksheet for Computing Binomial Probabilities of the Number
of Customers Who Click at Martin’s
Binomial distribution expected value and standard
deviation
• The expected value of a binomial distribution is ALWAYS: np
• The n is the number of trials (like emails sent)
• The p is the probability of “success” (like any individual email being opened)
• The standard deviation of a binomial distribution is ALWAYS:
• Sqrt(n*p*(1-p))
• Be careful with the word “success.” It typically just means “yes” so it
could be a “success” to have a disease!
Continuous Probability
Distributions
Uniform Probability Distribution
Triangular Probability Distribution
Normal Probability Distribution
Exponential Probability Distribution
Continuous Probability Distributions
• Fundamental difference separates discrete and continuous random
variables in terms of how probabilities are computed:
• Discrete random variables: the probability mass function f (x)
provides the probability that the random variable assumes a particular value.
• Continuous random variables – the counterpart of the probability mass
function is the probability density function, also denoted by f (x).
• The probability density function does not directly provide probabilities.
• We are computing the probability that the random variable assumes any value in
an interval.
• For continuous random variables, the probability of any particular value of
the random variable is zero.
Continuous Probability Distributions
Uniform Probability Distribution:
• Example: Random variable x representing the flight time of an airplane
traveling from Chicago to New York.
• With every interval of a given length being equally likely, the random
variable x is said to have a uniform probability distribution.
With continuous distributions…
• You can’t evaluate the probability of a SPECIFIC event! There is no
probability (p = 0) that a flight will land in exactly 131.6674 minutes!
• BUT you CAN evaluate the probability of a RANGE of a specific
event…You do this by finding the AREA of under the graph
corresponding to your range
• Thus, the reason the probability of any SPECIFIC event occurring (like
the 131.6674 minute flight) is 0 is because there is no WIDTH (only
height) to one LINE… and area is calculated as width x height!
Continuous Probability Distributions
Uniform Probability Distribution for Flight Time
Continuous Probability Distributions
Figure 4.18: The Area Under the Graph Provides the Probability of a
Flight Time Between 120 and 130 Minutes
This is an example…of course…
• What about circling the airport in case of an external emergency, etc!
Continuous Probability Distributions
• Like with the discrete probability functions, an advantage to having data
that follows a SPECIFIC TYPE (the word is “parametric”), such as uniform or
binomial, is that we can quickly calculate things like expected return and
variance! (literally…the data follows certain PARAMETERS!)
• For uniform continuous probability distribution, the formulas for the
expected value and variance (take square root for standard dev) are:
𝑎+𝑏
=
2
(𝑏−𝑎)2
=
12
𝐸 𝑥
Var 𝑥
• It’s very powerful to know that data are “parametric” in a given way. It
allows us to go past just expected returns and standard deviations…It
allows us to talk about the PROBABILITY of events in specific, powerful
ways without a lot of extra work!
• e.g., We know the probability of exactly one Martin email being answered is 0.441
• e.g., We know the probability of the plane landing between 125 and 130 minutes is
0.25
Tying it together!
• As you might have realized…the key to doing things like using t-tests and
normal tables is the ASSUMPTION that data is parametric…and in the case
of t-tests and normal tables, that the SPECIFIC parameters are the NORMAL
parameters! In fact, the normal distribution is so powerful and common
that often people refer to “parametric” tests or procedures when they
specifically mean just “NORMAL” parametric tests or procedures (like using
t-tests and normal tables to make conclusions regarding probability).
• When you use t-tests and normal tables, you’re using the fact that data is
parametrically normal in order to quickly be able to learn things about the
probabilities of certain things occurring!
• Like a given student having an IQ over 130
• Or like the amount of CO2 being given off by a plant being between 10 and 13 tons a day
Continuous Probability Distributions
Normal Probability Distribution:
• One of the most useful probability distributions for describing a continuous
random variable is the normal probability distribution.
• Wide variety of practical and business applications:
• Heights and weights of people.
• Test scores.
• Scientific measurements.
• Uncertain quantities such as demand for products.
• Rate of return for stocks and bonds.
• Time it takes to manufacture a part or complete an activity.
• All you’re really saying is that the most likely types of values are those near
the middle of the range (unlike the uniform, e.g.), and that as you get
FURTHER AWAY from this middle, the likelihood decreases
• It turns out…that you can say this about a lot of phenomena in the world!
Continuous Probability Distributions
Bell-Shaped Curve for the Normal Distribution
Continuous Probability Distributions
• The probability density function that defines the bell-shaped curve of
the normal distribution is:
Continuous Probability Distributions
Characteristics of the normal distribution:
1. The entire family of normal distributions is differentiated by two
parameters: the mean and the standard deviation .
This makes normal data very powerful…because if you know the mean
and standard deviation, and you know it’s normal…you know
EVERYTHING! And that’s why you can quickly move toward making
declarations regarding the probability of certain normally distributed
things occurring!
2. The highest point on the normal curve is at the mean, which is also the
median and mode of the distribution.
3. The mean of the distribution can be any numerical value: negative, zero,
or positive.
Continuous Probability Distributions
Characteristics of the normal distribution (continued):
4. The normal distribution is symmetric, with the shape of the normal
curve to the left of the mean a mirror image of the shape of the
normal curve to the right of the mean.
5. The tails of the curve extend to infinity in both directions and
theoretically never touch the horizontal axis.
6. The standard deviation determines how flat and wide the normal
curve is; larger values of the standard deviation result in wider, flatter
curves, showing more variability in the data.
Continuous Probability Distributions
Three Normal Distributions with the Same Standard Deviation but
( = −10, = 0, = 20)
Different Means
Continuous Probability Distributions
Two Normal Distributions with the Same Mean but Different Standard
( = 5, = 10)
Deviations
Continuous Probability Distributions
Characteristics of the normal distribution (continued):
7. Probabilities for the normal random variable are given by areas under the
normal curve. The total area under the curve for the normal distribution is
1. Because the distribution is symmetric, the area under the curve to left of
the mean is 0.50 and the area to the right is 0.50.
8. The percentages of values in some commonly used intervals are:
a.
b.
c.
68.3% of the values of a normal random variable are within plus or minus one
standard deviation of its mean.
95.4% of the values of a normal random variable are within plus or minus two
standard deviations of its mean.
99.7% of the values of a normal random variable are within plus or minus
three standard deviations of its mean.
These just happen to be the amounts within 1, 2, or 3 deviations…so it’s
common to commit them to memory. But the normal is so easy to use
that we can quickly interpret things like -1.33 deviations or 2.96
deviations with the use of a table or computer!
Continuous Probability Distributions
Areas Under the Curve for Any Normal Distribution
Continuous Probability Distributions
• Application of the normal probability distribution: Grear Aircraft Engines
sells aircraft engines to commercial airlines.
• Grear offers performance-based sales contract guaranteeing that engines
will provide certain amount of lifetime flight hours subject to airline
purchasing a preventive-maintenance service plan.
• Based on extensive flight testing and computer simulations, Grear
believes mean lifetime flight hours is normally distributed with a mean
= 36,500 hours and standard deviation = 5,000 hours.
• What is the probability that an engine will last more than 40,000 hours?
Continuous Probability Distributions
Grear Aircraft Engines Lifetime Flight Hours Distribution
Continuous Probability Distributions
Excel Calculations for Grear Aircraft Engines Example
Continuous Probability Distributions
• Grear is considering a guarantee that will provide a discount on a
replacement aircraft engine if the original engine does not meet the
lifetime-flight-hour guarantee.
• How many lifetime flight hours should Grear guarantee if Grear wants
no more than 10% of aircraft engines to be eligible for the discount
guarantee?
• How do we calculate the probability that an engine will have a
lifetime of flight hours greater than 30,000 but less than 40,000
hours?
Continuous Probability Distributions
Grear’s Discount Guarantee
Continuous Probability Distributions
Graph Showing the Area Under the Curve Corresponding to
P ( 30,000 x 40,000 ) in the Grear Aircraft Engines Example
Continuous Probability Distribution
Using Excel to Find P(30,0005
Interval Estimation
Normal Approximation of the Sampling Distribution of 𝑝lj
Interval Estimation
95% Confidence Interval for Survey of Women Golfers
Hypothesis Tests
Developing Null and Alternative Hypothesis
Type I and Type II Errors
Hypothesis Test of the Population Mean
Hypothesis Test of the Population Proportion
Practical significance
Hypothesis Tests
• The tentative conjecture is called the null hypothesis
• The opposite of what is stated in the null hypothesis is the alternative
hypothesis
• The hypothesis testing procedure uses data from a sample to test the validity
of the two competing statements about a population
• The typical thing to do is create a (boring) baseline case as the NULL
hypothesis…THEN the researcher suggests an alternative hypothesis that
he/she believes might actually be true
• e.g., does taking the supplement improve bone density?
• Null (H0) hypothesis is that those taking the supplement are the same (or worse)
• Alternative (Ha) hypothesis is that those taking the supplement are better
• THEN the question becomes…how MUCH better must a SAMPLE be in order
for us to believe the alternative hypothesis about the POPULATION and
disregard the null hypothesis!?
Hypothesis Tests
Developing Null and Alternative Hypotheses:
• Context of the situation is very important in determining how the
hypotheses should be stated.
• All hypothesis testing applications involve collecting a random sample
and using the sample results to provide evidence for drawing a
conclusion.
• Ask:
• What is the purpose of collecting the sample?
• What conclusions are we hoping to make?
• Be careful and have high standards regarding non-sampling
error. It is not the researcher/analyst’s job to introduce bias to
make it LOOK like there’s a statistically significant difference
when there’s not one!
Hypothesis Tests
• Many applications of hypothesis testing involve an attempt to gather
evidence in support of a research hypothesis—best to begin with the
alternative hypothesis and make it the conclusion that the researcher
hopes to support.
• Not all hypothesis tests involve research hypothesis:
• Begin with a belief or a conjecture that a statement about the value of a
population parameter is true.
• Use a hypothesis test to challenge the conjecture and determine whether
there is statistical evidence to conclude that the conjecture is incorrect.
• Helpful to develop the null hypothesis first; the alternative hypothesis is
that the belief or conjecture is incorrect.
Hypothesis Tests
Developing Null and Alternative Hypotheses (cont.):
• Depending upon the situation, hypothesis tests about a population
parameter may take one of three forms:
• The first two use inequalities in the null hypothesis.
• Third one uses an equality in the null hypothesis:
H0 : 0
H0 : 0
H0 : = 0
Ha : 0
Ha : 0
Ha : 0
• First two forms are called one-tailed tests.
• Third form is called a two-tailed test.
• The two-tailed form allows more flexibility, but it’s less powerful!
Hypothesis Tests
Type I and Type II Errors
• First row shows what can happen if the conclusions is to accept H0
• If H0 is true, this conclusion is correct
• If Ha is true, we made a Type II error (accepted H0 when it is false)
• Second row shows what can happen if the conclusion is to reject H0
• If H0 is true, we made a Type I error (rejected H0 when it is true)
• If Ha is true, rejecting H0 is correct
Hypothesis Tests
• Level of Significance:
• The level of significance is the probability of making a Type I error
when the null hypothesis is true as an equality.
• The person responsible for the hypothesis test specifies the level of
significance and the probability of making a Type I error.
• Applications of hypothesis testing that only control the Type I error
are called significance tests.
• Most applications of hypothesis testing control the probability of
making a Type I error; they do not always control the probability of
making a Type II error.
Hypothesis Tests
Hypothesis Test of the Population Mean:
• One tailed tests about a population mean take one of the following
forms:
Upper-Tail Test
Lower-Tail Test
H0 : 0
H0 : 0
Ha : 0
Ha : 0
1. Develop the null and alternative hypothesis for the test.
2. Specify the level of significance for the test.
3. Collect the sample data and compute the value of what is called a test
statistic.
Hypothesis Tests
Sampling Distribution of 𝑥lj for the Hilltop Coffee Study
When the Null Hypothesis Is True as an Equality (𝜇 = 3 𝑝𝑜𝑢𝑛𝑑𝑠)
Hypothesis Tests
• Use the t-distributed random variable t as a test statistic to
determine whether x deviates from the hypothesized value of
enough to justify rejecting the null hypothesis
• The key question for a lower-tail test is: How small must the test
statistic t be before we choose to reject the null hypothesis?
Hypothesis Tests
• In order to answer, it’s typical to use a P-value
• P-Value:
A p value is the probability, assuming that H0 is true, of obtaining a
random sample of size n that results in a test statistic at least as
extreme as the one observed in the current sample.
Hypothesis Test About a Population Mean
It sure looks like Hilltop’s coffee is LESS than 3 lbs per
can…
2.92 pounds (as a sample mean) is obviously less than
3…
BUT is it SIGNIFICANTLY less than 3 so that statistically
we’re confident this is a methodical difference? (which
would of course benefit the company and might even be
intentional)..
That’s what the t-test and the p-value are all about!
P-value of 0.0078 means it’s LESS than 1% likely we’d get
such a low sample mean if the POPULATION mean is
3lbs per can.
p Value for the Hilltop Coffee Study When x =
2.92 and s = 0.17
It’s easiest in Excel (or with an old “normal table”
to quickly get the p-values with these “left tail”
questions
But to do the right tail, you can calculate the pvalue of the left side (which in such cases is usually
high… like 0.949 or 0.991) and subtract it from 1
To do a TWO-TAILED test (say you wanted to test
whether a weird looking coin was fair and so you
were testing if its proportion of heads was
0.50…NOT more OR less) you find whether your tstat is positive or negative. If negative, do the quick
“left tail” calculation and double it. If positive, do
the 1-left side calculation then double THIS!
Hypothesis Tests
• The level of significance indicates the strength of evidence that is needed in the
sample data before rejection of the null hypothesis.
• Different decision makers may express different opinions concerning the cost of
making a Type I error and may choose a different level of significance.
• Sometimes, in research, we even joke about using 10% (rather than the most typical 5%) in
some contexts because then we can ‘convict’ (reject the null) more easily!
• Providing the p value as part of the hypothesis testing results allows decision
makers to compare the reported p value to his or her own level of significance.
Hypothesis Tests
For an upper-tail test, the p value is the probability of obtaining a value
for the test statistic as large as or larger than that provided by the
sample.
Computation of p Values for One-Tailed Tests:
1. Compute the value of the test statistic using equation.
2. Lower-tail test: Using the t distribution, compute the probability that t is
less than or equal to the value of the test statistic (area in the lower tail).
3. Upper-tail test: Using the t distribution, compute the probability that t is
greater than or equal to the value of the test statistic (area in the upper
tail).
Hypothesis Tests
In hypothesis testing, the general form for a two-tailed test about
population mean is:
H0 : = 0
Ha : 0
Hypothesis Tests
p Value for the Holiday
Toys Two-Tailed
Hypothesis Test
Hypothesis Tests
Two-Tailed Hypothesis Test for
Holiday Toys
Hypothesis Tests
Computation of p Values for Two-Tailed Tests:
1. Compute the value of the test statistic using equation.
2. If the value of the test statistic is in the upper tail, compute the
probability that t is greater than or equal to the value of the test
statistic (the upper-tail area). If the value of the test statistic is in
the lower tail, compute the probability that t is less than or equal
to the value of the test statistic (the lower-tail area).
3. Double the probability (or tail area) from step 2 to obtain the p
value.
Hypothesis Tests
Summary of Hypothesis Tests About a Population Mean
Hypothesis Tests
Steps of Hypothesis Testing:
Step 1. Develop the null and alternative hypotheses.
Step 2. Specify the level of significance.
Step 3. Collect the sample data and compute the value of the test
statistic.
Step 4. Use the value of the test statistic to compute the p value.
Step 5. Reject H0 if the p .
Step 6. Interpret the statistical conclusion in the context of the
application.
Hypothesis Tests
A two-sided hypothesis and a confidence interval are really going to tell you the same thing!
They’re analogous!
e.g., if you JUST BARELY fail to reject the null hypothesis of a population mean of 9 pounds,
then 9 pounds is JUST BARELY going to make it into your confidence interval
Hypothesis Tests
Hypothesis Test of the Population Proportion:
• The three forms for a hypothesis test about a population proportion
are:
H0 : p p0
H0 : p p0
H0 : p = p0
Ha : p p0
Ha : p p0
Ha : p p0
• The first form is called a lower-tail test.
• The second form is called an upper-tail test.
• The third form is called a two-tailed test.
Hypothesis Te...
Essay Writing Service Features
Our Experience
No matter how complex your assignment is, we can find the right professional for your specific task. Achiever Papers is an essay writing company that hires only the smartest minds to help you with your projects. Our expertise allows us to provide students with high-quality academic writing, editing & proofreading services.
Free Features
Free revision policy
$10Free bibliography & reference
$8Free title page
$8Free formatting
$8How Our Dissertation Writing Service Works
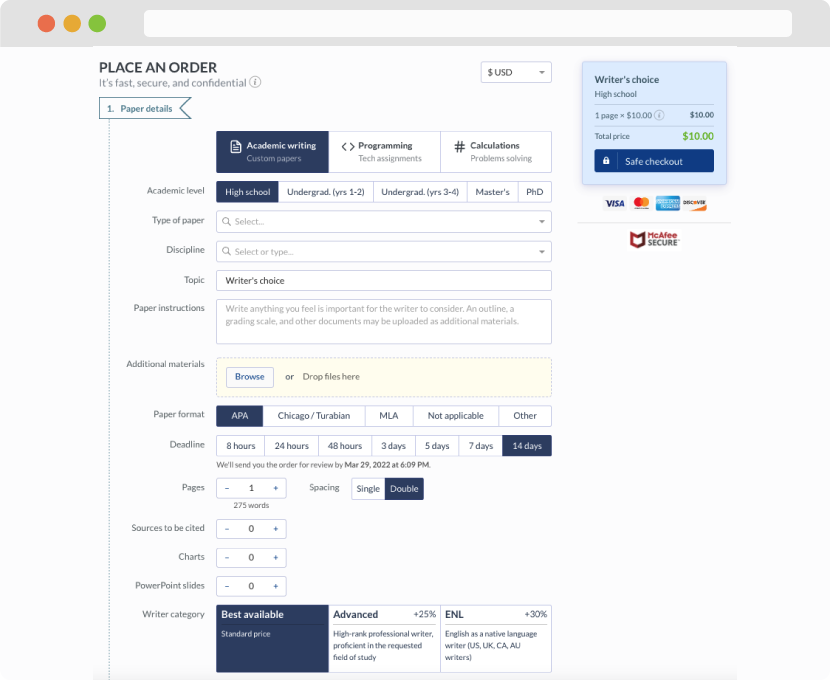
First, you will need to complete an order form. It's not difficult but, if anything is unclear, you may always chat with us so that we can guide you through it. On the order form, you will need to include some basic information concerning your order: subject, topic, number of pages, etc. We also encourage our clients to upload any relevant information or sources that will help.
Complete the order form
Once we have all the information and instructions that we need, we select the most suitable writer for your assignment. While everything seems to be clear, the writer, who has complete knowledge of the subject, may need clarification from you. It is at that point that you would receive a call or email from us.
Writer’s assignment
As soon as the writer has finished, it will be delivered both to the website and to your email address so that you will not miss it. If your deadline is close at hand, we will place a call to you to make sure that you receive the paper on time.
Completing the order and download